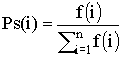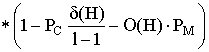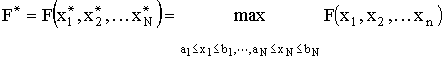Здесь я постараюсь изложить основные операции предлагаемого поискового
алгоритма. Он несколько отличается от традиционного генетического алгоритма, как
в построении символьной модели, так и в структуре самого алгоритма. Об истории
появления генетических алгоритмов и о том, для каких задач они применяются
читайте в главе "Популярно о
генетических алгоритмах".
Задача поиска
Прежде чем приступать к описанию поискового алгоритма, следует определиться с
тем, что мы будем понимать под задачей поиска.
Предполагается, что целью задачи поиска является нахождение объекта с
некоторыми свойствами. Как правило, поиск производится среди конечного (иногда и
бесконечного) множества объектов (потенциальных решений).
Первый шаг при решении задачи поиска состоит в том, чтобы определиться
относительно объектов этого множества. Т.е. нужно четко представлять себе класс
исследуемых объектов. Будем называть это множество объектов пространством
объектов и обозначим его O. Примером O может служить пространство
n-мерных векторов вещественных чисел, множество шахматных позиций или множество
вариантов раскройки ткани.
Второй шаг, который должен предшествовать процедуре поиска состоит в выборе
некоторого представления объектов из пространства O. Представление
определяется множеством S - пространством представлений. S
выбирается с таким расчетом, что алгоритму поиска будет легче манипулировать
членами S, чем O. Как правило, S не равно O, хотя
это и не всегда обязательно.
В отличие от пространства объектов, пространство представлений обязательно
конечное. В реальных задачах в реальном времени вместо O принято
рассматривать его конечное подмножество O'. Отображение между элементами
O и S будет называть представлением. Представление
описывает связь между исследуемыми объектами, которые выступают в качестве
потенциальных решений задачи поиска, и объектам, управлением и манипулированием
которых занимается поисковый алгоритм. Представление есть функция кодирования
e: O -> S
Для o из O и s из S запись
s=e(o) будет обозначать то, что s является
представлением o. В общем случае e(o) может описывать
целое множество представлений, однако этот случай нами не рассматривается.
Обратное отношение будем записывать как e-1 (функция
декодирования)
e-1: S -> O
обратное отношение используется тогда, когда по новому представлению
s' из S, полученному в результате поиска, требуется восстановить
соответствующее ему решение o' из O.
e-1(o) может представлять множество объектов из
O. Если e(o') - не пустое множество, то будем говорить,
что o' представлен. Если e-1(s') - пустое
множество, то s' - недопустимое представление.
Использование представлений позволяет осуществлять поиск практически при
минимуме информации о характере и свойствах пространства объектов. Как правило
бывает достаточно только той информации, которая позволяет описать ландшафт в
пространстве представлений.
Среди различных типов задачи поиска наибольший интерес для нас представляет
задача в которой требуется найти лучший, на сколько это возможно при
существующих ограничениях (временных или каких-либо еще), объект o*. При
этом на множестве объектов O должна быть определена функция цели
f(o), позволяющая сравнивать решения
f: O -> R
такая, чтобы для любых двух o1,o2 из
O, если f(o1)>f(o2), то
o1 считается решением лучше, чем o2.
R - множество вещественных чисел. Очевидно, что об оптимальности того или
иного решения можно говорить лишь тогда, когда исследовано все пространство
представлений S.
Для реализации алгоритма поиска в пространстве представлений можно ввести
функцию оценки представлений, аналогично функции f, определенной на
элементах из множества O. Определим ее как
m: S -> R
Где R - множество вещественных чисел.
С помощью m можно определить порядок в
S таким образом, чтобы представителям лучших объектов в смысле f
соответствовало большее значение m. Т.е. если для любых
двух объектов o1, o2 из O в S
определены различными представителями s1=e(o1) и
s2=e(o2), s1 не равно
s2 и если f(o1)>f(o2), то
m(s1)>m(s2). В общем случае функцией m(s) может быть любая функция M,
удовлетворяющая этому условию.
m(s) =
M(f(e-1(s)))
Однако, как правило, вполне достаточно сделать
m(s) = f(e-1(s))
Иногда, в зависимости от конкретных операторов алгоритма поиска, бывает
необходимо, что функция m(s) принимала положительные
значения.
Представленные рассуждения позволяют сформулировать задачу поиска наилучшего
объекта o* из множества O следующим образом
o* = argmax f(e-1(s)) s из S
Ее решение осуществляется поиском в пространстве S оптимального
представления s*:
s* = argmax m(s) s из S
Еще раз, прежде чем построить поисковый алгоритм нужно определиться с
символьной моделью задачи, которая включает в себя
пространство потенциальных решений O,
пространство представлений S,
функцию кодирования e и декодирования e-1,
функцию цели f,
функция оценки представлений m.
Постановка задачи
Нами будет рассматриваться общая задача непрерывной оптимизации
max f(x), где D = {x = (x1,
x2, :, xN) | xi на [ai,
bi], i=1, 2,:N} x из D
(1)
f(x) - максимизируемая (целевая) скалярная многопараметрическая
функция, которая может иметь несколько глобальных экстремумов, прямоугольная
область D - область поиска, D - подмножество RN.
Предполагается, что о функции f(x) известно лишь то, что она
определена в любой точке области D. Никакая дополнительная информация о
характере функции и ее свойствах (дифференцируемость, липшицируемость,
непрерывность и т.д.) не учитывается в процессе поиска.
Под решение задачи (1) будем понимать вектор x =
(x1, x2, :, xN).
Оптимальным решением задачи (1) будем считать вектор x*, при котором
целевая функция f(x) принимает максимальное значение. Исходя из
предположения о возможной многоэкстремальности f(x), оптимальное решение
может быть не единственным.
В принятых ранее обозначениях под объектом будем понимать точку x в
многопараметрическом пространстве O=D в RN. Роль
функции цели будет играть максимизируемая функция f(x).
Символьная модель
Для того, чтобы построить пространство представлений под генетический
алгоритм для задачи непрерывной оптимизации, нужно помнить, что начиная с 1975 -
публикации первого издания книги Голланда - ГА-мы использовались при решении
комбинаторных задачам оптимизации. Использование аппарата для решения дискретных
задач применительно к задачам непрерывной оптимизации допускалось путем
дискретизации пространства параметров скалярной функции f(x), для которой
предстояло найти оптимальное решение.
Параметры x обычно кодируются бинарной строкой s. Используя
целевую функцию f(x) можно построить функцию m(s) - функцию пригодности или, как она называется в
генетических алгоритмах, функция приспособленности, отобразив, когда это
необходимо, f на положительную полуось. Это делается для того, чтобы
гарантировать прямое соотношение между значение целевой функции и
приспособленностью решения, и затем такая модифицированная целевая функция
рассматривается как функция приспособленности ГА. Таким образом, каждое
возможное решение s, имеющее соответствующую приспособленность m(s), представляет решение x.
Обычно, переход из пространства параметров в хемминингово пространство
бинарных строк осуществляется кодированием переменных x1,
x2, :, xN в двоичные целочисленные строки
достаточной длины - достаточной для того, чтобы обеспечить желаемую точность.
Желаемая точность в этом случае и будет тем отправным условием, которое
определяет длину бинарных строк. Для этого пространство параметров должно быть
дискретизировано таким образом, чтобы расстояние между узлами дискретизации
соответствовало требуемой точности. Предположим, по условию задачи с функцией от
двух переменных x1 и x2, определенной на
прямоугольной области D = {0
<x1<1; 0<x2<1}, требуется локализовать
решение x* с точностью по каждому из параметров 10-6. Для
достижения такой точности пространство параметров дискретизуется равномерной
сеткой с (bi-ai)/(10-6)= 1/10-6 =
1000000 узлами по каждой координате. Закодировать такое количество узлов можно
l = 20 битами, где l определяется из условия 106 <
2l+1. Вот и получается, что общая длина бинарной строки
кодировки для двумерной задачи составит 2X20 = 40 бит.
При таком способе кодирования значения варьируемых параметров решений будут
располагаться по узлам решетки, дискретизующей D. Соответственно, если
кодировки двух решений будут совпадать, то будут совпадать и значения параметров
обоих решений.
Во многих случаях такая, казалось бы, естественная модель может оказаться
неэффективной. Кроме того, что она достаточно громоздка (Во что превратится
хемминингово пространство поиска для задачи с сотней параметров?!), практика
показывает, что длинная кодировка повышает вероятность "преждевременной"
сходимости, для борьбы с которой изобретаются различные уловки. К тому же
применение длинных кодировок вовсе не гарантирует, что найденное решение будет
обладать требуемой точностью, поскольку этого, в принципе, не гарантирует сам
ГА.
Мы представим модификацию символьной модели, позволяющей, не применяя длинных
кодировок, добиваться сравнимой точности.
Итак, чтобы провести дискретизацию пространства D и закодировать
каждое возможное решение строкой s, как и прежде "погрузим" равномерную
сетку в пространство параметров. Для этого проделаем следующее.
Каждый интервал [ai, bi] разбиваем на k отрезков равной
длины:
hi = (bi - ai) / k, i = 1, 2, :N.
Этом самым покроем i-ый интервал [ai, bi] сетью
si из (k+1) узла с постоянным шагом hi.
xi,j = ai + j.hi, j =
0, 1, : k.
Используя двоичный алфавит {0,1} каждому узлу сетки si
можно присвоить уникальный бинарный код длины q. Длина
кода q выбирается таким образом, чтобы k <
2q. Наиболее целесообразно и экономично
использовать сетку с k = 2q-1.
Тогда символьная запись j-ого узла по i-ой координатной оси в двоичном коде
можно представить в виде следующей бинарной конструкции
b1i
b2i
...
bqi
Проведя дискретизацию по всем N координатным осям, получим в N-мерном
параллелепипеде D пространственную решетку S с (k+1)N узлом,
где каждый узел s можно представить в виде линейной последовательности
таких записей (хромосом).
s =
b11
b21
...
bq1
...
b1N
b2N
...
bqN
Таким образом, чтобы построить символьную модель непрерывной оптимизационной
задачи на гиперкубе D нужно представить множество узлов пространственной
решетки S с помощью бинарных последовательностей (хромосом).
ГА оперирует строками фиксированной длины.
Чтобы применять ГА к задаче, сначала выбирается метод кодирование решений в
виде строки. Фиксированная длина (l-бит, l=q*N) двоичной кодировки означает, что любая из
2l возможных бинарных строк представляет возможное решение
задачи.
По существу, такая кодировка соответствует разбиению пространства параметров
на гиперкубы, которым соответствуют уникальные комбинации битов в строке -
хромосоме. Для установления соответствия между гиперкубами разбиения области и
бинарными строками, описывающими номера таких гиперкубов, кроме обычной двоичной
кодировки использовался рефлексивный код Грея. Код Грея предпочтительнее
обычного двоичного тем, что обладает свойством непрерывности бинарной
комбинации: изменение кодируемого числа на единицу соответствует изменению
кодовой комбинации только в одном разряде.
Идея ГА состоит в том, чтобы манипулируя имеющейся совокупностью бинарных
представлений, с помощью ряда генетических операторов получать новые строки,
т.е. перемещаться в новые гиперкубики. Получив бинарную комбинацию для нового
решения, формируется вектор (операция декодирования e-1), со
значениями из соответствующего гиперкуба, используя равномерное распределение.
Таким образом, каждое решение генетического алгоритма будет иметь следующую
структуру:
Точка в пространстве параметров (фенотип):
x = (x1, x2, : xN) принадлежит
D из RN;
Бинарная строка s фиксированной длины, однозначно идентифицирующая
гиперкуб разбиения пространства параметров (генотип):
s = (b1, b2, :, bl)
принадлежит S,
где S - пространство представлений - бинарных строк длины
l.
Скалярная величина m, соответствующая значению
целевой функции в точке х (приспособленность):
m = f(x).
В терминологии, принятой в теории ГА, такую структуру принято называть
особью. Предлагаемая модель обязательно включает в себя вектор со значениями из
гиперкуба пространства параметров. Совокупность особей принято называть
популяцией.
Символьная модель, предлагаемых ранее генетических алгоритмов,
предусматривала дискретизацию пространства параметров с шагом, соответствующим
требуемой точности. При этом решением задачи (1) мог быть только узел
пространственной решетки, так что между точкой в параметрическом пространстве и
ее представителем в пространстве S существовало взаимно однозначное
соответствие. Предлагаемая же нами модель не предусматривает однозначности,
допуская существование целого множества решений, имеющих единого представителя.
В терминологии ГА это означает, что могут существовать особи, обладающие
различными фенотипическими признаками, но имеющие одинаковые генотипы (такое
явление, вообще говоря, встречается в природе, например, у однояйцовых
близнецов). Это позволяет использовать более крупное разбиение пространства
параметров, сужая пространство бинарных строк S и делая при этом длину
хромосомного набора короче. Многообразие точек, распределяемых в небольших
гиперкубиках, позволяет достигать высокой точности даже в тех задачах, где
решение не попадает в окрестность узла решетки.
Включение в символьную модель вектора со значениями из пространства
параметров может показаться избыточным, однако, такая модель предоставляет
исследователю больше свободы с манипулированием представления, в частности ниже
будут рассмотрены вопросы, связанные с динамическим изменением длины кодировки
на различных этапа поиска без потери лучших найденных решений.
Геометрическая интерпретация символьной модели
Итак, мы определись с тем, каким образом будет осуществляться переход из
евклидова пространства параметров в пространство представлений (бинарных строк).
Давайте рассмотрим эту процедуду на конкретном примере простой одномерной
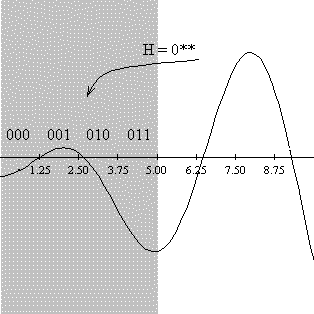
функции f(x).
f(x) = 10 + x sin(x),
определенной на отрезке [0, 10].
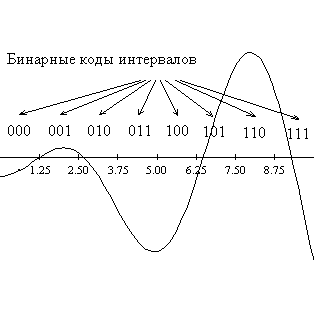
Пусть кодирование будет осуществляться бинарными строками длины 3. Т.е.
отрезок [0,10] нужно разбить на 23 = 8 подинтервалов, каждому из
которых будет соответствовать уникальная двоичная комбинация, получаемая
переводом номера подинтервала, считая слева направо, в двоичную системы. Длина
каждого такого интервала будет h=10:8=1.25.
Рисунок 1: Построение символьной модели для одномерной
задачи, используя трехбитовое представление.
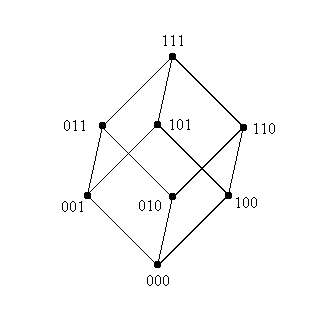
Пространством поиска, таким образом, становится множество всех бинарных строк
длины 3. Это пространство можно представить в виде трехмерного куба, вершинам
которого соответствуют кодовые комбинации, расставленные так, что хэмминингово
расстояние между смежными вершинами равно 1.
Рисунок 2: Пространство поиска для трехбитового
представления.
Задача алгоритма поиска заключается в том, чтобы, следуя некоторому правилу,
перемещаться в новые вершины этого куба, что будет соответствовать исследованию
новых подинтервалов в пространстве D.
Шима (schema)
Хотя внешне кажется, что ГА обрабатывает строки, на самом деле при этом
неявно происходит обработка шим, которые представляют шаблоны подобия между
строками (Гольдберг, 1989; Голланд, 1992). ГА практически не может заниматься
полным перебором всех представлений в пространстве поиска. Однако он может
производить выборку значительного числа гиперплоскостей в областях поиска с
высокой приспособленностью. Каждая такая гиперплоскость соответствует множеству
похожих строк с высокой приспособленностью.
Шима - это строка длины l (что и длина любой строки популяции),
состоящая из знаков алфавита {0;1;*}, где {*} - неопределенный символ. Каждая
шима определяет множество всех бинарных строк длины l, имеющих в
соответствующих позициях либо 0, либо 1, в зависимости от того, какой бит
находится в соответствующей позиции самой шимы. Например, шима, 10**1,
определяет собой множество из четырех пятибитовых строк {10001; 10011; 10101;
10111}. У шим выделяют два свойства - порядок и определенная длина.
Порядок шимы - это число определенных битов ("0" или "1") в шиме.
Определенная длина - расстояние между крайними определенными битами в шиме.
Например, вышеупомянутая шима имеет порядок o(10**1)=3, а определенная
длина d(10**1) = 4. Каждая строка в популяции является
примером 2l шим.
Вернемся к нашему примеру с одномерной функцией f(x)=10+x*sin(x) и
3-битными строками. Мы уже говорили, что пространство поиска в этом случае будет
трехмерным кубом. Давайте посмотрим, какую графическую интерпретацию получат
шимы.
Сначала исследуем шимы, чей порядок равен трем, т.е. все три бита в шаблоне
определены. Понятно, таких шим - всех бинарные комбинации длины 3. Нетрудно
сделать вывод, что в данном случае шимы порядки 3 будут соответствовать вершинам
куба.
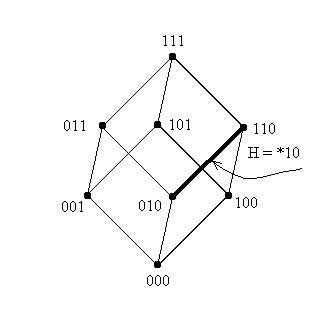
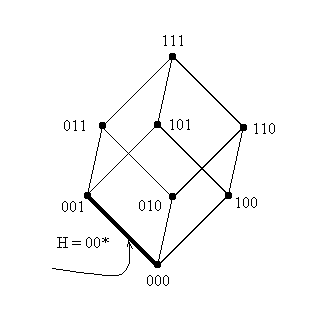
Теперь давайте посмотрим, чему буду соответствовать шаблоны порядка 2. Таких
шим 2o(H)Cll-o(H) =
22C31 = 12: {00*, 01*, 10*, 11*, 0*0, 0*1, 1*0,
1*1, *00, *01, *10, *11}. Геометрически, все такие шаблоны описывают
поверхности, размерность которых на единицу превосходит размерность точки -
вершины куба, т.е. шимы порядка 2 длины 3 соответствуют ребрам куба. Ниже
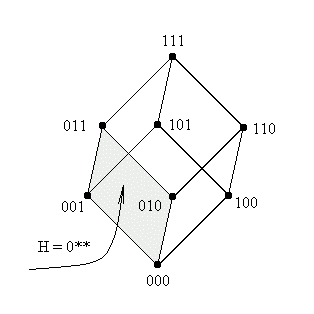
приводится графическая интерпретация шим H=(00*) и H=(*10).
Рисунок 2: Геометрическая интерпретация шаблонов порядка
2.
Точно также можно показать, чему соответствуют шаблоны, чей порядок равен 1.
Таких шим 6: {0**, 1**, *0*, *1*, **0, **1}. Все они представляют поверхности,
размерность которых на единицу больше размерности шим порядка 2, т.е. в нашем
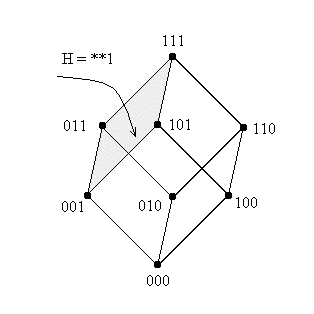
случае это грани куба. Вот, например, как выглядят шимы H=(**1) и H=(0**).
Рисунок 3: Геометрическая интерпретация шаблонов порядка
1.
Если же рассматривать единственную шиму порядка 0, т.е. в ней нет
определенных битов, то очевидно, что ее будет соответствовать весь куб.
До сих про мы рассматривали то, как шимы представлены в пространстве бинарных
строк. А чему они будут соответствовать в евклидовом пространстве параметров?
Чтобы ответить на этот вопрос давайте вспомним, как мы вводили функцию
кодирования и каким образом осуществляли переход в пространство представлений.
На примере одномерной функции это выглядело так: отрезок [a,b] разбивался на
2l подинтервалов равной длины и каждый такой интервал
кодировался бинарной последовательностью (см. Рисунок 1). Поскольку мы говорили,
что каждая шима определяет множество всех бинарных строк, имеющих в
соответствующих позициях либо 0, либо 1, в зависимости от того, какой бит
находится в соответствующей позиции самой шимы, то в пространстве параметров
шиме будет соответствовать объединение подинтервалов, бинарные представления
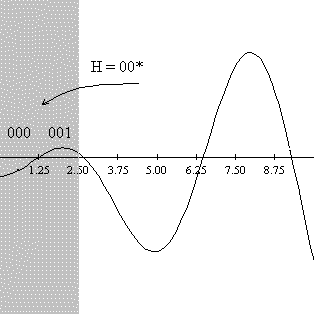
которых являются примерами этой шимы. Например, в рассматриваемой нами задаче
шимам H=(00*)и H=(*10) на отрезке [0,10] будут соответствовать следующие области
(на рисунке они выделены темным цветом).
Рисунок 4: Интерпретация шим порядка 2 в пространства
параметров.
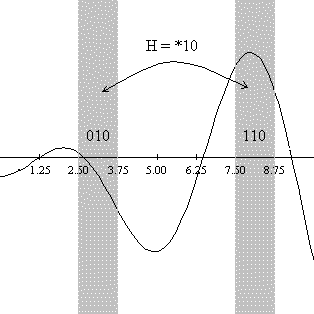
Шимы с меньшим порядком будут задавать более многочисленное множество
бинарных строк, поэтому в пространстве параметров они смогут охватить большую
область. Вот, например, как будут представлены шимы порядка 1 на нашем примере.
Рисунок 5: Интерпретация шим порядка 1 в пространства
параметров.
Строящие блоки
Строящие блоки (Goldberg, 1989c) - это шимы обладающие:
высокой приспособленностью,
низким порядком,
короткой определенной длиной.
Приспособленность шимы определяется как среднее приспособленностей примеров,
которые ее содержат.
После процедуры отбора остаются только строки с более высокой
приспособленностью. Следовательно строки, которые являются примерами шим с
высокой приспособленностью, выбираются чаще. Кроссовер реже разрушает шимы с
более короткой определенной длиной, а мутация реже разрушает шимы с низким
порядком. Поэтому, такие шимы имеют больше шансов переходить из поколения в
поколение. Голланд (1992) показал, что, в то время как ГА явным образом
обрабатывает n строк на каждом поколении, в тоже время неявно
обрабатываются порядка n3 таких коротких шим низкого порядка и
с высокой приспособленностью (полезных шим, "useful schemata"). Он называл это
явление неявным параллелизмом. Для решения реальных задач, присутствие неявного
параллелизма означает, что большая популяция имеет больше возможностей
локализовать решение экспоненциально быстрее популяции с меньшим числом особей.
Работа простого ГА
Имеются много способов реализации идеи биологической эволюции в рамках ГА.
Традиционным считается ГА, представленный на схеме.
НАЧАЛО /* простой генетический алгоритм*/
Создать начальную совокупность структур (популяцию)
Оценить каждую структуру
останов := FALSE
ПОКА НЕ останов ВЫПОЛНЯТЬ
НАЧАЛО /* новая итерация (поколение)
Применить оператор отбора
ПОВТОРИТЬ (размер_популяции/2) РАЗ
НАЧАЛО /* цикл воспроизводства */
Выбрать две структуры (родители) из множества предыдущей итерации
Применить оператор скрещивания с заданной вероятность к
выбранным структурам и получить две новые структуры (потомки)
Оценить эти новые структуры
Если оператор скрещивания не применяется,
то потомки становятся копиями своих родителей
Поместить потомков в новое поколение
КОНЕЦ
Применить оператор мутации с заданной верояностью
ЕСЛИ популяция сошлась ТО останов := TRUE
КОНЕЦ
КОНЕЦ
Простой ГА случайным образом генерирует начальную совокупность (популяцию)
структур (особей). Работа ГА представляет собой итерационный процесс, который
продолжается до тех пор, пока не выполнятся заданное число поколений или
какой-либо иной критерий остановки. На каждом поколении ГА реализуется отбор
пропорционально приспособленности, одноточечный оператор кроссовера и оператор
мутации. Сначала, пропорциональный отбор назначает каждой структуре вероятность
Ps(i) равную отношению ее приспособленности к суммарной приспособленности
популяции:
Затем происходит отбор (с замещением) всех n структур для дальнейшей
генетической обработки, согласно величине Ps(i). Простейший
пропорциональный отбор - рулетка (roulette-wheel selection, Goldberg, 1989c) -
отбирает особей с помощью n "запусков" рулетки. Колесо рулетки содержит
по одному сектору для каждого члена популяции. Размер i-ого сектора
пропорционален соответствующей величине Ps(i). При таком отборе члены
популяции с более высокой приспособленностью с большей вероятность будут чаще
выбираться, чем особи с низкой приспособленностью.
После отбора, n выбранных особей подвергаются кроссоверу (иногда
называемому рекомбинацией) с заданной вероятностью Pc. n строк
случайным образом разбиваются на n/2 пары. Для каждой пары с вероятность
Pc может применяться кроссовер. Соответственно с вероятностью 1-Pc
кроссовер не происходит и неизмененные особи переходят на стадию мутации. Если
кроссовер происходит, полученные потомки заменяют собой родителей и переходят к
мутации.
Одноточечный кроссовер работает следующим образом. Сначала, случайным образом
выбирается одна из l-1 точек разрыва. (Точка разрыва - участок между
соседними битами в строке.) Обе родительские структуры разрываются на два
сегмента по этой точке. Затем, соответствующие сегменты различных родителей
склеиваются и получаются два генотипа потомков.
Например, предположим, один родитель состоит из 10 нолей, а другой - из 10
единиц. Пусть из 9 возможных точек разрыва выбрана точка 3. Родители и их
потомки показаны ниже.
Кроссовер
Родитель 1
0000000000
000~0000000
->
111~0000000
1110000000
Потомок 1
Родитель 2
1111111111
111~1111111
->
000~1111111
0001111111
Потомок 2
После того, как закончится стадия кроссовера, выполняются операторы мутации.
В каждой строке, которая подвергается мутации, каждый бит с вероятностью Pm
изменяется на противоположный. Популяция, полученная после мутации записывает
поверх старой и этим цикл одного поколения завершается. Последующие поколения
обрабатываются таким же образом: отбор, кроссовер и мутация.
В настоящее время исследователи ГА предлагают много других операторов отбора,
кроссовера и мутации. Вот лишь наиболее распространенные из них. Прежде всего,
турнирный отбор (Brindle, 1981; Goldberg и Deb, 1991). Турнирный отбор реализует
n турниров, чтобы выбрать n особей. Каждый турнир построен на
выборке k элементов из популяции, и выбора лучшей особи среди них.
Наиболее распространен турнирный отбор с k=2.
Элитные методы отбора (De Jong, 1975) гарантируют, что при отборе обязательно
будут выживать лучший или лучшие члены популяции совокупности. Наиболее
распространена процедура обязательного сохранения только одной лучшей особи,
если она не прошла как другие через процесс отбора, кроссовера и мутации.
Элитизм может быть внедрен практически в любой стандартный метод отбора.
Двухточечный кроссовер (Cavicchio, 1970; Goldberg, 1989c) и равномерный
кроссовер (Syswerda, 1989) - вполне достойные альтернативы одноточечному
оператору. В двухточечной кроссовере выбираются две точки разрыва, и
родительские хромосомы обмениваются сегментом, который находится между двумя
этими точками. В равномерном кроссовере, каждый бит первого родителя наследуется
первым потомком с заданной вероятностью; в противном случае этот бит передается
второму потомку. И наоборот.
Теорема шим
Так почему же генетический алгоритм работает и локализует области с высокой
приспособленностью? Каким образом теория шим или шаблонов подобия проявляется в
работе ГА? Для того, чтобы ответить на эти вопросы и чтобы дать представление о
внутренних механизмах работы считаю необходимым кратко изложить основную теорему
генетических алгоритмов, известную как "теорема шим". Она показывает, каким
образом простой ГА экспоненциально увеличивает число примеров полезных шим или
строящих блоков, что приводит к нахождению решения исходной задачи.
Пусть m(H,t) - число примеров шимы H в t-ом поколении. Вычислим ожидаемое
число примеров H в следующем поколении или m(H,t+1) в терминах m(H,t). Простой
ГА каждой строке ставит в соответствие вероятность ее "выживания" при отборе
пропорционально ее приспособленности. Ожидается, что шима H может быть выбрана
m(H,t)*(f(H)/fср.) раз, где fср. - средняя
приспособленность популяции, а f(H) - средняя приспособленность тех строк
в популяции, которые являются примерами H.
Вероятность того, что одноточечный кроссовер разрушит шиму равна вероятности
того, что точка разрыва попадет между определенными битами. Вероятность же того,
что H "переживает" кроссовер не меньше 1-Pc*(d(H)/l-1). Эта вероятность - неравенство, поскольку
шима сможет выжить, если в кроссовере участвовал также пример похожей шимы.
Вероятность того, что H переживет точечную мутацию -
(1-Pm)o(H),это выражение можно аппроксимировать как (1-o(H))
для малого Pm и o(H). Произведение ожидаемого число отборов и
вероятностей выживания известно как теорема шим:
m(H,t+1)
Теорема шим показывает, что строящие блоки растут по экспоненте, в то время
шимы с приспособленностью ниже средней распадаются с той же скоростью.
Goldberg (1983, 1989c), в своих исследованиях теоремы шим, выдвигает гипотезу
строящих блоков, которая состоит в том, что "строящие блоки объединяются, чтобы
сформировать лучшие строки". То есть рекомбинация и экспоненциальный рост
строящих блоков ведет к формированию лучших строящих блоков.
В то время как теорема шим предсказывает рост примеров хороших шим, сама
теорема весьма упрощенно описывает поведение ГА. Прежде всего, f(H) и
fср. не остаются постоянными от поколения к поколению. Приспособленности
членов популяции знаменательно изменяются уже после нескольких первых поколений.
Во-вторых, теорема шим объясняет потери шим, но не появление новых. Новые шимы
часто создаются кроссовером и мутацией. Кроме того, по мере эволюции, члены
популяции становятся все более и более похожими друг на друга так, что
разрушенные шимы будут сразу же восстановлены. Наконец, доказательство теоремы
шим построено на элементах теории вероятности и следовательно не учитывает
разброс значений, в многих интересных задачах, разброс значений
приспособленности шимы может быть достаточно велик, делая процесс формирования
шим очень сложным (Goldberg и Rudnick, 1991; Rudnick и Goldberg, 1991).
Существенная разница приспособленности шимы может привести к сходимости к
неоптимальному решению.
Несмотря на простоту, теорема шим описывает несколько важных аспектов
поведения ГА. Мутации с большей вероятностью разрушают шимы высокого порядка, в
то время как кроссовера с большей вероятность разрушают шимы с большей
определенной длиной. Когда происходит отбор, популяция сходится пропорционально
отношению приспособленности лучшей особи, к средней приспособленности в
популяции; это отношение - мера давления отбора ("selection pressure", Back,
1994). Увеличение или Pc, или Pm, или уменьшении давления отбора,
ведет к увеличенному осуществлению выборки или исследованию пространства поиска,
но не позволяет использовать все хорошие шимы, которыми располагает ГА.
Уменьшение или Pc, или Pm, или увеличение давления выбора, ведет к
улучшению использования найденных шим, но тормозит исследование пространства в
поисках новых хороших шим. ГА должен поддержать тонкое равновесие между тем и
другим, что обычно известно как проблема "баланса исследования и использования".
Некоторые исследователи критиковали обычно быструю сходимость ГА, заявляя,
что испытание огромных количеств перекрывающихся шим требует большей выборки и
более медленной, более управляемой сходимости. В то время как увеличить выборку
шим можно увеличив размер популяции (Goldberg, Deb, и Clark, 1992; Mahfoud и
Goldberg, 1995), методология управления сходимость простого ГА до сих пор не
выработана.
Алгоритм
Предлагаемый в нашей работе ГА сохраняет основные принципы теории
эволюционно-генетического поиска: процесс поиска оптимального решения
описывается итерационным процессом моделируемой "эволюции", целью которой
является нахождение одной или нескольких структур (особей), имеющей максимальную
приспособленность, т.е. структуру, соответствующей оптимальному значению
управляемых параметров. Однако реализацию данного генетического алгоритма
отлична от традиционной схемы
НАЧАЛО /* генетический алгоритм */
/* формирование начальной совокупности решений P0
={aK0}*/
сгенерировать начальную совокупности строк S0
сформировать векторы начального множества решений
X0=e-1(S0)
оценить начальные решения P0: m
(S0)
t = 0 /* счетчик итераций */
/* процедура поиска */
ПОКА НЕ выполнено условия останова ПОВТОРИТЬ
НАЧАЛО
Rt=Pt/* репродукционное множество */
ДЛЯ p = 1 до p = Np ПОВТОРИТЬ
НАЧАЛО
выбрать ait и ajt из
Pt: ait, ajt =
B(Pt)
s2p-1t+1/2, s2pt+1/2 =
С(ait,ajt)
x2p-1t+1/2 =
e-1(s2p-1t+1/2)
x2pt+1/2 =
e-1(s2pt+1/2)
оценить новые решения a2p-1t+1/2 и
a2pt+1/2: m(s2p-1t+1/2) и m(s2pt+1/2)
Rt = Rt U
{a2p-1t+1/2,a2pt+1/2}
КОНЕЦ
С вероятность Pm для каждого решения (k=1,2,:) ПОВТОРИТЬ
НАЧАЛО
s2Np+kt+1/2 = M(am),
am из Rt
x2Np+kt+1/2 =
e-1(s2Np+kt+1/2)
оценить новое решение a2Np+kt+1/2: m(s2Np+kt+1/2)
Rt = Rt U {a2Np+kt+1/2}
КОНЕЦ
Оператор отбора S: Rt -> Pt+1
t = t+1
КОНЕЦ
КОНЕЦ
Прежде всего отличие от классических ГА-мов состоит в сохранении вещественных
векторов решений. Вторым важным отличием является порядок реализации основных
генетических операторов. Вначале проходит стадия "воспроизводства" новых
решений, включающая в себя три элемента:
Выбор элементов ait и ajt
(брачная пара), используя правило B /breeding/.
Генерация новых решений с помощью оператора "кроссовер"
C /crossover/
Локальные изменения большого числа решений с помощью оператора "мутации"
M /mutation/.
И лишь затем осуществляется процедура построения совокупность решений для
следующей итерации ("поколения") из всего множества доступных к тому моменту
решений - оператор S.
В-третьих, представленный алгоритм, относится скорее к так называемым
"поколенческим" (термин ДеЯнга) эволюционным алгоритмам, в которых эволюция идет
от одной итерации к другой, допуская появление k>>1 новых решений,
накапливаемых в репродукционном множестве, прежде, чем включится процесс отбора,
отбрасывающий лишние k решений.
Поскольку алгоритм построен таким образом, что решения, получаемые в
результате кроссовера, не заменяют собой "родителей" (как в традиционном ГА), то
такой параметр как Pc - вероятность кроссовера - в данном случае не нужен
(или всегда равен 1.0). Вместо него мы пользуемся параметром, описывающим число
брачных пар. Управлять количеством вычислений целевой функции, т.е. количеством
генерируемых решений предпочтительнее этим детерминированным параметром.
На каждом из этапов предлагаются альтернативные генетические операторы.
Некоторые из них уже известны и описаны в литературе (Mitchell, 1996), появление
других обусловлено новизной символьной модели. Все они по-разному влияют на
поведение ГА. Подробнее к этому вопросу мы еще вернемся. А пока, я еще раз
остановлюсь на списке основных параметров ГА:
мощность множества решений Pt(численность популяции),
длина бинарных кодировок s(длина генотипов),
количество решений, генерируемых на каждой итерации,
вероятность применения оператора локального изменения решений (мутации)
M,
правило B выбора двух решений,
тип используемого оператора глобального поиска (кроссовера)
С,
тип используемой оператора локального изменения (мутации) М,
процедура отбора S.
Почти все из них (кроме численности популяции) могут динамически изменяться
от итерации к итерации.
Очевидно, что восемь параметров - это достаточно много для алгоритма. То,
насколько удачным окажется применение ГА при решении той или иной задачи, во
многом будет определяться их удачной настройкой. Вообще говоря, строгих правил,
универсальных для всех задач, нет и быть не может (по теореме "не бывает
бесплатных обедов" /"no free lunch" theorem, Wolpert & McReady, 1995/),
однако в данной работе мы постараемся сформулировать некоторые рекомендации по
настройке параметров для решения определенного класса задач.
И последнее замечание. Поскольку предлагаемый генетический алгоритм
отличается от других, разумно было бы условиться сравнивать ГА по
"алгоритмонезависимым" признакам. Сравнение по числу итераций (поколений) мне
представляется неуместным, поскольку эта характеристика скорее относится к
свойствам алгоритма, а не к качеству получаемых решений. Наибольший интерес,
конечно же, представляет задача минимизации числа оценок целевой функции при
соблюдении требуемой точности. И именно эту характеристику мы считаем
определяющей при вынесении вердикта о том, насколько пригоден или непригоден ГА
для решения той или иной задачи. Мы исходим из предположения, что раз ГА-мы
создаются для решения реальных задач, то основное время поиска решения должно
складываться из оценок реальной модели (мощность газовой турбины или ситуация на
фондовом рынке), возможно путем проведения дорогостоящих испытаний, а ускорить
работу самого алгоритма можно гораздо проще, например используя вычислительную
систему помощнее.
Если у Вас есть замечания, предложения или пожелания относительно
представленного здесь материала - просьба связаться с автором.