|
АТД Словарь используется для манипулирования набором элементов, встроенных в линейном порядке. Он поддерживает динамическое редактирование элементов (создание, внесение и удаление) и различные формы поиска внутри набора (например, поиск заданного элемента, наименьшего, наибольшего элемента, предшественника или последователя элемента).
Основными характеристиками словаря являются затраты на вставку элемента, удаление и поиск. Однако некоторые реализации словарей позволяют эффективно выполнять другие дополнительные операции, такие как объединение словарей, переход к большему/меньшему соседу и т.п. Оценки времени для таких эффективно выполняемых операций мы также будем также включать в таблицы.
Как правило, для эффективного доступа словари организуются на основе упорядоченных структур данных. Если такого упорядочения нет, то оно вводится. Например: лексикографический порядок для строк, порядок для треугольников значению координаты x самой левой вершины. Зачастую алгоритм, использующий словарь в качестве структуры данных, сам подсказывает необходимый порядок.
Списки
Простейший словарь можно реализовать в виде списка элементов в порядке их поступления.
| Характеристики несортированного списка: |
|
вставка |
поиск |
удаление |
объединение словарей |
| время |
O(1) |
O(n) |
O(n)* |
O(1) |
| память |
один-два указателя на каждый элемент данных |
|
Если дополнительно поддерживать упорядоченность этого списка, то имеем следующие оценки:
| Характеристики сортированного списка: |
|
вставка |
поиск |
удаление |
переход к большему/меньшему элементу |
| время |
O(n) |
O(n) |
O(n)* |
O(1) |
| память |
один-два указателя на каждый элемент данных |
|
* - чтобы удалить данные из списка, их нужно сначала найти.
Двоичные деревья
В ряде приложений, где не требуется быстрый поиск и удаление произвольного элемента, и где ценны дополнительные преимущества, предоставляемые структурой списка, такой выбор представляется оптимальным. Однако весьма часто от словаря требуются гораздо лучшие основные характеристики.
Хорошим выбором может послужить двоичное дерево поиска.
Характеристики двоичного дерева поиска:
(основные операции стоят одинаково) |
|
среднее |
худшее |
| время |
O(logn) |
O(n) |
| память |
два указателя на каждый элемент данных |
|
Реальное время выполнения операций зависит от формы дерева. Если оно похоже на список - имеем O(n), как в списке, если на дерево - то O(log n). Можно доказать, что при последовательном включении в дерево случайных данных получается именно среднее время выполнения операций. Однако, если входные данные, например, образуют возрастающую последовательность, то получается список и все преимущество дерева потеряно.
На практике двоичные деревья поиска очень удобны во многих приложениях, где входные данные случайны или есть другие причины надеяться на сохранение деревом хорошей формы. Существуют способы добиться времени O(log n) на любых входах, они полезны, но дают небольшие накладные расходы на хранение специальной информации.
Есть одна задача, которая не может быть эффективно решена с помощью двоичных деревьев поиска: для заданного элемента в двоичном дереве поиска найти ближайшие больший и меньший элементы. Хотя при симметричном обходе все элементы выстраиваются в порядке увеличения, это не позволяет эффективно определить предшественника и последователя для произвольного элемента.
Проблема может быть эффективно решена с помощью пополнения структуры двоичного дерева. Классическим решением являются связанные двоичные деревья поиска, которые являются двоичными деревьями поиска со связным списком, охватывающим все узлы в порядке возрастания.
| | 
| Обходы бинарных деревьев
Существует достаточно много алгоритмов работы с древовидными структурами, в которых часто встречается понятие обхода (traversing) дерева или "прохода" по дереву. При таком методе исследования дерева каждый узел посещается только один раз, а полный обход задает линейное упорядочивание узлов, что позволяет упростить алгоритм, так как при этом можно использовать понятие "следующий" узел. т.е. узел стоящий после данного при выбранном порядке обхода.
|
Улучшенные двоичные деревья
Очевидно, поиск осуществляется тем быстрее, чем ближе к корню расположен искомый элемент. В идеале двоичное дерево поиска сбалансировано, т. е. его форма такова, что каждый элемент располагается сравнительно близко к корню. Сбалансированное двоичное дерево поиска размера n имеет высоту O(log n), в предположении, что путь от корня до каждого узла имеет длину более, чем O(log n). Но совсем несбалансированное дерево поиска имеет высоту O(n); поиск в таком дереве так же неэффективен, как в связанном списке.
|
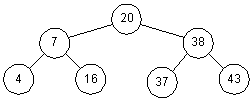
Рис. 1: Сбалансированное двоичное дерево
|
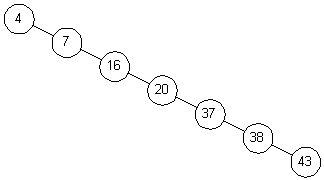
Рис. 2: Несбалансированное двоичное дерево
|
Причин, по которым дерево может стать плохо сбалансированным, несколько. Во-первых, во многих приложениях входной поток элементов не обязательно будет случайным (в крайнем случае элементы вводятся в возрастающем или убывающем порядке и получающееся дерево в большинстве случаев оказывается несбалансированным). Во-вторых, порядок операций поиска (перемежающихся с операциями ввода) может быть непредсказуем (поиск недавно введенных элементов может оказаться особенно дорогим, поскольку элемент может оказаться на самом нижнем уровне двоичного дерева). В третьих, ожидаемые свойства деревьев поиска, получившихся после выполнения операций удаления не всегда хорошо понятны.
В этом подразделе будут расмотрены различные вариации двоичных деревьев, позволяющие добиться более стабильной, а, значит, более быстрой работы.
Один из подходов заключается в балансировке дерева после каждой операции. Таким образом получаются строгие ограничения на высоту узла, и, как следствие, гарантированная оценка O(logn) для операций.
| | 
| АВЛ-деревья z i p
При помощи вращений дерево балансируется таким образом, что высота узла не более, чем на 44% превышает минимальную возможную для двоичных деревьев.
|
| Красно-черные деревья
Узлы раскрашиваются в два цвета, следуя правилам. Некоторые сочетания цветов объявляются неправильными и от них избавляются путем вращений. Высота узла не более, чем в 2 раза превышает минимальную возможную для двоичного дерева. С исходником на Си.
|
Несколько заметок.
- Верхние оценки высот листов для АВЛ-деревьев и красно-черных деревьев разные, но на практике деревья сбалансированы примерно одинаково;
- Красно-черные деревья при правильной реализации лучше, чем АВЛ-деревья. Дело в том, что вставка и удаление элемента можно осуществить за один проход по дереву: сверху вниз[подробнее читайте здесьzip]. В АВЛ-деревьях требуется сначала пройти вниз, произвести операцию, а потом сделать балансирующий проход обратно вверх;
- Реализация АВЛ-деревьев и красно-черных деревьев может быть как рекурсивной, так и итеративной.
Для АВЛ-деревьев рекурсивная реализация работает в 1.5-2 раза медленнее. Красно-черные деревья, ввиду возможности вставки/удаления за один проход, также имеют большое преимущество при итеративной реализации.
Другой подход заключается в рандомизации алгоритма, то есть введения датчика случайных чисел, от которого (а не от входной последовательности) и будет зависеть форма дерева. Таким образом, дерево получается 'случайным', с оценкой O(log n).
| |
| Деревья со случайным поиском
Каждому узлу сопоставляется приоритет - случайное число, доопределяющая место элемента дополнительно к самому ключу. Структура также обеспечивает быструю операцию нахождения большего/меньшего элемента. С исходником на С++.
|
| Слоёные списки (скип-списки)
Вероятнастная альтернатива сбалансированным деревьям. Проста в реализации и почти так же эффективна, как деревья. Основана на сопоставлении словаря и записной книжки. Как правило, медленнее деревьев. С исходником на Си.
|
Другие словари
| |
| Хеш-таблицы
Лучший выбор, если не нужна сортировка информации, а только быстрый доступ к ней. Тратится дополнительная память.
|
| Б, Б+ и Б++ деревья
Предназначены для индексации больших словарей на диске. Б-деревья читают несколько ключей при одном обращении к диску, минимизируя обращения, а значит, и связанные с этим большие задержки.
|
Несколько особняком стоят хэш-таблицы. Их поведение сильно зависит от коэффициента заполненности. Реальное ухудшение результатов при закрытом хэшировании появляется после заполнения таблицы на 80%. Асимптотически основные операции требуют O(1) в среднем и O(n) - в худшем случае. На практике хэш-таблицы работают гораздо быстрее, чем деревья, но при использовании хэш-таблиц сложно эффективно реализовать какие-либо другие операции, кроме основных.
Б-деревья и их вариации дают очень большой рост в скорости при работе с файлами.
|