Декомпозиция на монотонные полигоны методом сканирующей линии
По книге Ласло, "Вычислительная геометрия и компьютерная графика на С++"
Декомпозиция полигонов на монотонные части
В этом разделе представим алгоритм для декомпозиции произвольного полигона на монотонные подполигоны, этот процесс иногда называют регуляризацией. Алгоритм использует сканирование на плоскости для регуляризации n-угольника за время О(n log n). Используя этот алгоритм совместно со способом триангуляции монотонных полигонов, выполняемым за линейное время, мы получим алгоритм для триансуляции произвольного полигон за время О(n log n): сначала выполним декомпозицию заданного полигона на монотонные подполигоны, затем осуществим триангуляцию каждого из них по очереди.
Для упрощения описания ниже в этом разделе будем предполагать, что никакие две вершины в полигоне не имеют одинаковой координаты х.
В алгоритме применяется подход сканирующей линии: воображаемая прямая идет по плоскости слева направо, пересекая объекты и останавливаясь в точках-событиях - точках на плоскости, достижение которых вызывает изменение состояния алгоритма. При остановке линии происходит обработка соответствующего события.
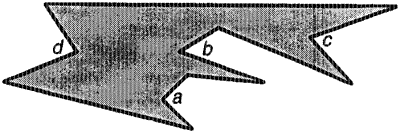
Наш алгоритм основан на определении понятия излома. Вогнутая вершина — вершина, внутренний угол которой превышает 180 градусов — является изломом, если обе ее соседние вершины лежат либо слева, либо справа от нее (рис. 1). Легко видеть, что никакой монотонный полигон не может содержать излом. Это правило обратимо и выражается следующей теоремой, лежащей в основе алгоритма:
Теорема о монотонности полигона: любой полигон, не содержащий излома, является монотонным.
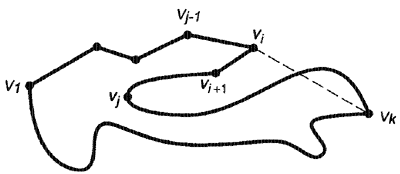
Теорема доказывается от противного: если полигон Р немонотонный, тогда в нем есть излом. Предположим, что полигон Р немонотонный и его немонотонность является следствием того, что его верхняя цепочка не является монотонной. Обозначим вершины вдоль верхней цепочки полигона Р как v1, v2,..., vk и пусть vi будет первой вершиной вдоль цепочки такой, что вершина vi+1 будет лежать слева от vi (рис. 1). Если вершина vi+1 лежит над ребром vi-1vi, тогда vi будет изломом, так что мы предположим, что вершина vi+1 находится под vi-1vi. Пусть vj будет самой левой вершиной цепочки от vi до vk, прежде чем цепочка пересечет ребро vivk . Вершина vj является вогнутой, поскольку она локально самая левая и внутренность полигона лежит слева от нее, эта же вершина vj является изломом, поскольку она вогнутая и обе соседние с ней вершины находятся справа от нее. Таким образом теорема доказана.
Программа верхнего уровня
Наш алгоритм выполняется путем декомпозиции полигона Р на подполи-гоны без изломов. В первой из двух фаз по мере продвижения сканирующей линии по прямоугольнику R слева направо алгоритм удаляет изломы, направленные влево, формируя набор подполигонов P1, P2,..., Рm ни один из которых не содержит изломов, направленных влево. Во время второй фазы алгоритм удаляет изломы, направленные вправо, продвигая сканирующую линию справа налево по подполигонам Pi по очереди. Полученная коллекция полигонов и будет декомпозицией исходного полигона Р на подполигоны, в которых нет ни право-, ни лево-направленных изломов и, следовательно, совсем никаких изломов.
В программу regularize передается полигон р и она возвращает список монотонных полигонов, представляющих регуляризацию исходного полигона р. В процессе работы программы исходный полигон р разрушается. Реализация использует класс кольцевого списка и классы из раздела структуры геометрических данных. В качестве класса Dictionary можно использовать любой словарь, поддерживающий требуемые операции. Например, можно переопределить #define Dictionary RandomizedSearchTree.
enum ( LEFT_TO_RIGHT, RIGHT_TO_LEFT); // слева-направо, справа-налево
List<Polygon*> *regularize(Polygon &p)
{
// фаза 1
List<Polygon*> *polysl = new List<Polygon*>;
semiregularize(p, LEFT_TO_RIGHT, polys1);
// фаза 2
List<Polygon*> *polys2 = new List<Polygon*>;
polysl->last();
while (!polysl->isHead()) {
Polygon *q = polysl->remove();
semiregularize(*q, RIGHT_TO_LEFT, polys2);
}
return polys2;
}
Рис. 1: Вершины a, b и с соответствуют лево-направленным изломам, а вершина d — право-направленному излому
Рис. 2: Иллюстрация обязательного наличия излома в немонотонном полигоне
В этой программе полигоны, создаваемые в первой фазе, накапливаются в списке polysl, а формируемые во второй фазе - в списке polys2.
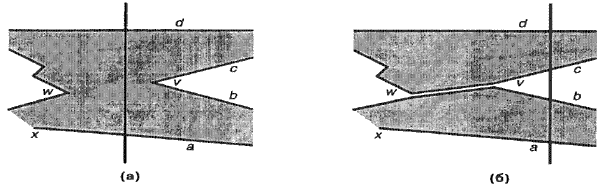
Основное назначение функции semiregularize заключается в исключении всех изломов, направленных в одну сторону. Например, при обращении semiregularize (р, LEFT_TO_RIGHT, polysl) выполняется сканирование полигона р слева направо и удаляются изломы, направленные влево, а получающиеся подполигоны добавляются в список polysl. Каждый раз, когда сканирующая линия обнаруживает направленные влево изломы v, полигон разбивается вдоль хорды, соединяющей v с некоторой вершиной w, расположенной слева от v. Чтобы отрезок прямой линии vw был действительно хордой (т. е. внутренней диагональю) полигона, выбор вершины w должен быть оправданным. Если вершина v лежит между активными ребрами а и d в качестве вершины w выбирается самая правая из тех вершин, что лежат между ребрами а и d и расположены слева от сканирующей линии (рис. 3).
Выбор вершины w можно пояснить и другим способом: рассмотрим трапецоид, образованный сканирующей линией, ребром а, ребром d и прямой линией, параллельной сканирующей линии и проходящей через точку х. Здесь в качестве точки х можно выбрать левую концевую точку ребер а или d, лежащую правее другой. Вершина w должна быть самой правой вершиной, лежащей внутри этого трапецоида, но если внутри трапецоида нет других вершин, то такой вершиной w будет вершина х. Вершину w будем называть целевой вершиной пары ребер a-d (вертикально соседней пары ребер a и d).
На рис. 3б показаны действия, предпринимаемые, когда сканирующая линия обнаруживает излом v: полигон расщепляется по хорде vw. Ни в одном из полученных новых полигонов вершина и уже не будет изломом — в каждом новом полигоне одна из соседних с v вершин лежит слева, другая — справа. Конечно, такая ситуация обеспечивается при перемещении сканирующей линии слева направо: ни одна из вершин, лежащих слева от сканирующей линии, не может быть изломом, указывающим влево.
Рис. 3: Действия, выполняемые при обнаружении излома v, направленного влево
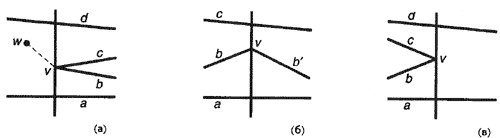
Переход выполняется каждый раз как только сканирующая линия обнаруживает вершину полигона. Тип перехода зависит от типа вершины, если вершины классифицировать в соответствии с положением их двух соседей относительно направления сканирования:
Начальная вершина: обе соседние вершины для вершины и располагаются после сканирующей линии, т. е. в направлении перемещения сканирующей линии.
Вершина перегиба: одна из соседних вершин находится сзади от сканирующей линии, другая — впереди.
Концевая вершина: обе соседние с и вершины расположены позади сканирующей линии.
Три взаимосвязанных перехода — начальный переход, переход при перегибе и концевой переход — показаны на рис. 4, где предполагается, что сканирование осуществляется в направлении слева направо. Типы перехода определены в терминах направления сканирования, так что функция semiregularize может быть использована при сканировании в любом направлении.
Рис. 4: Три вида переноса, возникающие при перемещении сканирующей линии слева направо
В обращении к функции semiregularize задается произвольный полигон р и указывается направление сканирования: LEFT_TO_RIGHT для обнаружения изломов, указывающих влево, и RIGHT_TO_LEFT для обнаружения изломов, указывающих вправо. Получающиеся в результате подполигоны добавляются в список polys. В функции используются три глобальные переменные:
int sweepdirection; // текущее направление сканирования
double curx; // текущая позиция сканирующей линии
int curtype; // текущий тип перехода
void semiregularize(Polygon &p, int direction, List<Polygon*> *polys)
{
sweepdirection = direction;
int (*cmp)(Vertex*, Vertex*);
if (sweepdirection==LEFT_TO_RIGHT) cmp = leftToRightCmp;
else cmp = rightToLeftCmp;
Vertex **schedule = buildSchedule(p, cmp);
Dictionary<ActiveElement*> sweepline = buildSweepline();
for (int i = 0; i < p.size(); i++) {
Vertex *v = schedule[i];
curx = v->x;
switch (curtype = typeEvent(v, cmp)) {
case START_TYPE:
startTransition(v, sweepline);
break;
case BEND_TYPE:
bendTransition(v, sweepline);
break;
case END_TYPE:
endTransition(v, sweepline, polys);
break;
}
}
p.setV(NULL);
}
Точки-события возникают при обнаружении вершин полигона. Поскольку все они известны заранее, то перечень точек-событий записан в массиве вершин, предварительно отсортированном в порядке увеличения координаты х (поэтому нет необходимости в динамической пересортировке словаря). Перечень формируется функцией buildSchedule, которой передается одна из функций сравнения точек leftToRightCmp или rightToLeftCmp в зависимости от направления сканирования:
Vertex **buildSchedule(Polygon &p, int(*cmp) (Vertex* , Vertex*)) {
Vertex **schedule = new (Vertex*) [p. size()];
for (int i = 0; i < p.size(); i++, p.advance (CLOCKWISE) )
schedule [i] = p.v();
insertionSort (schedule, p.size(), cmp); // сортировка с функцией сравнения cmp
return schedule;
}
Чтобы определить, какой тип перехода должен быть соотнесен с данной вершиной, в функции semiregularize используется функция typeEvent. Для классификации вершины v функция typeEvent проверяет положение двух соседних с ней вершин относительно направления сканирования:
int typeEvent (Vertex *v, int (*cmp) (Vertex* , Vertex*) )
{
int a = (*cmp) (v->cw(), v);
int b = (*cmp) (v->ccw(), v);
if ((a <= 0) && (b <= 0)) return END_TYPE;
else if ( (a > 0) && (b > 0) ) return START_TYPE;
else return BEND_TYPE;
}
Структура сканирующей линии
Структура сканирующей линии представляется в виде словаря(возможно использование класса RandomizedSearchTree, как показано в начале статьи) активных ребер, т. е. тех ребер полигона, которые пересекают сканирующую линию в данный момент, упорядоченных по увеличению координаты у. Кроме того, структура сканирующей линии содержит точку с минимальной координатой у (лежащую ниже всех ребер), служащую в качестве стража. Мы будем представлять структуру сканирующей линии в виде словаря объектов ActiveElement.
class ActiveElement {
public :
int type; // ACTIVE_EDGE (ребро) или ACTIVE_POINT (точка)
ActiveElement (int type);
virtual double у (void) = 0;
virtual Edge edge(void) { return Edge(); };
virtual double slope(void) { return 0.0; };
};
Конструктор ActiveElement инициализирует элемент данных type, который показывает, является ли элемент ребром или точкой:
Остальные компонентные функции класса ActiveElement являются виртуальными и они будут обсуждены несколько позже, в контексте двух производных классов.
Активные ребра представляются в виде объектов класса ActiveEdg
e:
class ActiveEdge : public ActiveElement {
public :
Vertex *v;
Vertex *w;
int rotation;
ActiveEdge (Vertex *_v, int _r, Vertex *_w);
Edge edge (void);
double у (void);
double slope (void);
};
Элемент данных v указывает на одну из концевых точек текущего ребра, a v->cw() — на другой конец. Элемент данных w является целевой вершиной пары ребер, состоящей из текущего ребра и активного ребра, расположенного непосредственно над ним. Элемент данных rotation используется для отслеживания связи от текущего ребра к ребру, которое может пересекать текущее ребро за сканирующей линией: если такое ребро существует, то v->neighbor (rotation) определяет окно на ребре.
Конструктор ActiveEdge определяется непосредственно:
Компонентная функция у возвращает координату у точки пересечения текущего ребра со сканирующей линией. Компонентные функции edge и slope возвращают текущее ребро и наклон текущего ребра соответственно. Эти три функции определяются как:
Структура сканирующей линии формируется так, чтобы она могла содержать точки наряду с ребрами, поскольку она должна обеспечивать операции определения положения точки в такой форме: для данной точки на сканирующей линии найти пару активных ребер, между которыми находится данная точка. Вот поэтому мы и определили класс ActiveElement так, чтобы получить из него производные классы, один для представления ребер и второй — для представления точек. Для целей поиска внутри структуры сканирующей линии мы будем представлять точку в виде объекта класса ActivePoint:
class ActivePoint : public ActiveElement {
public:
Point p;
ActivePoint (Point&);
double у(void);
};
Конструктор класса определим как:
ActivePoint::ActivePoint (Point &_p) :
ActiveElement (ACTIVE_POINT), p (_p)
{
}
Компонентная функция у просто возвращает координату у текущей точки
double ActivePoint::у (void)
{
return р.у;
}
Определив необходимые классы, перейдем к рассмотрению структуры сканирующей линии. Структура сканирующей линии создается с помощью функции buildSweepline. Функция инициализирует новый словарь и сохраняет активную точку, служащую в качестве стража — точку, расположенную ниже любого ребра, которое будет записано в словарь впоследствии:
Dictionary<ActiveElement*> &buildSweepline ()
{
Dictionary<ActiveElement*> *sweepline =
new Dictionary<ActiveElement*> (activeElementCmp);
sweepline->insert (new ActivePoint (Point (0.0, -DBL_MAX)));
return *sweepline;
}
Функция сравнения activeElementCmp применяется для сравнения двух активных элементов:
int activeElementCmp (ActiveElement *а, ActiveElement *b)
{
double ya = a->y();
double yb = b->y();
if (ya < yb) return -1;
else if (ya > yb) return 1;
if ( (a->type == ACTIVE_POINT) && (b->type == ACTIVE_POINT))
return 0;
else if (a->type == ACTIVE_POINT) return -1;
else if (b->type == ACTIVE_POINT) return 1;
int rval = 1;
if ( (sweepdirection==LEFT_TO_RIGHT && curtype==START_TYPE) ||
(sweepdirection==RIGHT_TO_LEFT && curtype==END_TYPE) )
rval = -1;
double ma = a->slope();
double mb = b->slope();
if (ma < mb) return rval;
else if (ma > mb) return -rval;
return 0;
}
Функция activeElementCmp вначале сравнивает активные элементы а и b на основе координат у их точек пересечения со сканирующей линией. Если они пересекаются в одной и той же точке, то считается, что активная точка расположена под активным ребром. Если оба элемента а и b являются активными ребрами, то для определения, какое из них лежит ниже другого, используются их соответствующие параметры наклона. Если предположим, что сканирование осуществляется слева направо, то ребро с меньшим коэффициентом наклона расположено ниже другого, если точка-событие является начальной вершиной, и выше другого, если точка-событие является конечной вершиной. Если предположим, что сканирование производится справа налево, то роли начальной и конечной вершин взаимно меняются местами (например, начальная вершина при сканировании слева направо становится конечной вершиной при сканировании в противоположном направлении).
Переходы
Рассмотрим теперь, как обрабатывать переходы, начиная с первого (рис. 4а). Когда сканирующая линия достигает начальной вершины v, то мы должны сначала отыскать в структуре сканирующей линии два активных ребра a и d, между которыми лежит вершина v. Если вершина v является точкой встречи ребер b и с, то b и с заносятся в структуру сканирующей линии и вершина v будет считаться целевой вершиной для пар ребер а-b, b-с и c-d. Кроме того, если вершина v является вогнутой (означающее, что v является изломом), то полигон, которому принадлежит вершина v, расщепляется вдоль хорды, соединяющей вершины v и w. В результате получается функция startTransition:
Разбиение полигона v в функции startTransition выполняется с помощью функции Vertex::split, вместо Polygon::split, поэтому нет необходимости знать, какому полигону принадлежит вершина v. По мере перемещения сканирующей линии в сторону вершины v в результате выполнения операции split формируются новые полигоны и вершина v может мигрировать из одного полигона в другой. Работая на уровне вершин, а не погигонов, мы можем избежать необходимости отслеживать, какому полигону принадлежит каждая вершина.
При обращении к функции isConvex(v) возвращается значение TRUE, если вершина v выпуклая, или значение FALSE в противном случае (вершина v вогнутая).
Функция определяется в виде:
bool isConvex (Vertex *v)
{
Vertex *u = v->ccw();
Vertex *w = v->cw();
int с = w->classify (*u, *v);
return ( (c == BEYOND) I I (c == RIGHT) );
}
Для обработки перехода для точки перегиба в вершине перегиба v сначала требуется найти в структуре сканирующей линии ребра a, b и с и принять вершину v в качестве целевой вершины для пар ребер а-b и b-с (рис. 4б). Затем ребро b в структуре сканирующей линии заменяется на ребро b', которое встречается с ребром b в вершине v. Таким образом получаем функцию bendTransition:
Для обработки концевого перехода в концевой вершине и сначала в структуре сканирующей линии найдем активные ребра а, b, с и d (рис. 4в). С одной стороны, если вершина v выпуклая, тогда v должна быть самой крайней правой вершиной полигона. Если это не так, то полигон, которому принадлежит вершина и, должен был бы обладать изломом, указывающим влево и расположенным слева от и, что противоречило бы условию сканирования. Поскольку вершина v является самой правой вершиной в полигоне, то на этот раз полигон добавляется в список polys. С другой стороны, если вершина v вогнутая, то v становится целевой вершиной для пары ребер a-d, а ребра b is. с удаляются из структуры сканирующей линии. Функцию endlransition получаем в следующем виде:
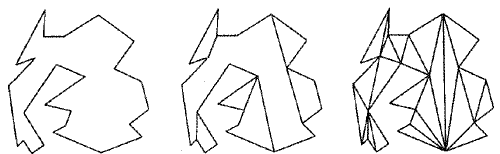
На рис. 5 показан результат регуляризации 25-угольника. При сканировании слева направо удаляются четыре излома, направленных влево, и один — направленный вправо (одна из операций расщепления split удаляет два излома одновременно). При последующем сканировании справа налево удаляются два оставшихся излома, направленных вправо, и получаются семь монотонных полигонов. Каждый из этих полигонов подвергается триангуляции с использованием алгоритма для монотонных полигонов.
Рис. 5: Результат разбиения 25-угольника на семь монотонных областей с их последующей триангуляцией
Анализ
Проведем анализ работы программы regularize для входного полигона, имеющего п вершин. По мере выполнения программы после ряда последовательных обращений к функции semiregularize общее число вершин увеличивается на две вершины после каждого выполнения операции расщепления split. Однако, поскольку не более, чем n/2 вершин исходного полигона могут быть изломами, то может быть добавлено не более, чем 2(n/2) = n вершин, что дает в результате не более 2n вершин. Так как каждая вершина может возбудить не более двух переходов (по одному на каждое направление сканирования), то всего может потребоваться выполнить не более 4n переходов.
Время выполнения перехода каждого типа определяется в основном небольшим постоянным числом операций со словарем, что занимает время O(log n). Поскольку всего выполняется О(n) переходов, то весь алгоритм выполняется за время О(n log n).