Если мы будем переставлять кадр A с соседним с ним справа, пока A не пройдет всю ленту Мебиуса и не вернется на свое место, то окажется, что стороны кадра поменяются - то, что раньше было A1 станет B1, и наоборот.
Разрежем ленту. Из замечания выше следует, что мы можем полагать, что на одной стороне ленты в каждом кадре написано минимальное из чисел, находящихся на сторонах кадра. Упорядочиваем элементы этой стороны ленты по неубыванию, Если и на другой стороне элементы выстроились по неубыванию, и при этом последний элемент первой стороны не превышает первого элемента второй стороны, то поставленная задача решена, иначе упорядочение невозможно.
Основная стратегия решения заключается в том, что каждый следующий камень кладется в кучу с меньшим текущим весом. При этом в первую кучу надо положить камень максимального веса. Покажем, что этого достаточно, чтобы гарантировать правильное решение задачи. По окончании распределения камней по кучам возможны 2 ситуации:
1. Все камни попали во вторую кучу, а ее вес остался меньше половины веса первой кучи. Понятно, что в этом случае камни требуемым образом разбить нельзя, следовательно решения не существует.
2. Случай 1. не верен. Тогда возможны следующие ситуации.
а) Все камни попали во вторую кучу. В этом случае ясно, что веса куч отличаются не более чем на половину первой кучи, если вес первой кучи больше, или не более чем вес последнего камня, положенного во вторую кучу. В любом из этих случаев требуемое условие выполняется.
б) В первую кучу попали и другие камни. Тогда ясно, что веса куч отличаются не более чем на вес самого тяжелого камня, кроме первого. Следовательно и в этом случае условие задачи выполняется.
На начальном этапе в первую кучу кладется самый тяжелый камень, а во вторую - два следующих по весу камня. Для оставшихся камней реализуется описанная для задачи 2 стратегия.
Алгоритм состоит в следующем. На каждом шаге находится человек Х, имеющий наибольшее число Р нереализованных знакомств. Затем находится Р людей, с которыми человек Х собирается реализовать знакомства. Нетрудно понять, что это должны быть люди опять же с наибольшим числом нереализованных знакомств, так как такая стратегия обеспечивает на каждом шаге максимально возможное количество людей с нереализованными еще знакомствами. Человек Х реализует по одному знакомству с каждым из Р выбранных людей и из дальнейшего процесса исключается. При этом число нереализованных знакомств у каждого из Р людей уменьшается на 1. Процесс продолжается до тех пор, пока все знакомства не будут реализованы, или найдется такой человек Х, которому не хватит людей для реализации его нереализованных знакомств. В последнем случае задача не имеет решения. Для поиска человека Х и Р людей для реализации знакомств достаточно каждый раз упорядочивать значения нереализованных знакомств в порядке невозрастания, сохраняя при этом информацию о "имени" (исходном номере) человека.
Мы можем отсортировать оба массива - и A, и B (например, по неубыванию), далее, если первые элементы массивов A и B совпадают, то ищем и в A, и в B минимальные элементы, большие данного, и повторяем сравнения; если же элементы не совпадают, либо один из массивов уже закончился, а другой еще нет, то массивы не похожие.
{A и B уже отсортированы}
i:=1; j:=1; {смотрим массивы A и B, начиная с первых элементов}
while (i<=10) and (j<=15) and (A[i]=B[j]) do
begin
element:=A[i];
while (i<=10) and (A[i]=element) do
i:=i+1; {поиск несовпадающего элемента}
while (j<=15) and (B[j]=element) do
j:=j+1; {поиск несовпадающего элемента}
end;
if (i=11) and (j=16) {просмотрели все элементы A и B}
then writeln('Массивы похожи')
else writeln('Массивы непохожи');
Каждому слову приписываем его номер в словаре. Сначала сортируем буквы в каждом слове по (например) неубыванию. Получаем какой-то "ключ", который совпадает у всех слов-анаграмм (например, слова 'лом' и 'мол' преобразуются в одни и те же ключи 'лмо').
Далее мы сортируем ключи слов (совместно с приписанными номерами) по неубыванию. Все одинаковые ключи будут размещаться в отсортированной последовательности слов друг за другом. Мы просматриваем полученную последовательность, ищем совпадающие ключи и по приписанным им номерам находим в словаре соответствующие слова-анаграммы.
Для каждой буквы заведем отдельный 'черпак', в который будем 'складывать' букву. Это можно сделать, используя массив А из 255 элементов. При этом номер 'черпака', соответствующего некоторой букве, определяется кодом буквы (известно, что любая буква кодируется некоторым двоичным числом, содержащим 8 цифр - называемых битами; в Паскале по букве определить ее код можно с помощью функции ord). При просмотре множеств подсчитаем, сколько раз встречалась каждая буква. Это делается следующим образом. При встрече буквы содержимое соответствующего ей элемента массива увеличиваем на 1. При этом начальное содержимое элементов массива - 0. После просмотра букв всех множеств элементы А определяют количество соответствующих букв, а значит и количество множеств, которым принадлежит соответствующая буква (ведь в одном множестве все элементы различны!). Используя аналогичным образом массив В из 255 элементов (больше не нужно, так как искомое число к по условию не превышает числа букв) подсчитаем количество единиц, двоек и т.д. в массиве А. Максимальное значение индекса к, для которого к=В[к] и будет решением поставленной задачи.
Достаточно отсортировать отрезки в порядке неубывания координат левых концов. После этого осуществляется простой просмотр упорядоченных отрезков с анализом следующих возможных ситуаций:
1. Если текущий отрезок пересекается с закрашиваемым отрезком (его левая координата не больше правого конца закрашиваемого отрезка), то новым правым концом закрашиваемого сейчас отрезка становится более правый из концов закрашиваемого и текущего отрезков.
2. Если текущий отрезок не пересекается с закрашиваемым отрезком, то закраска предыдущего отрезка закончена, его длина суммируется с длиной уже закрашенной части, а закрашиваемым отрезком становится текущий отрезок.
Процесс продолжается до тех пор, пока не будут просмотрены все отрезки. После этого длина последнего закрашенного отрезка суммируется с длиной ранее закрашенной части.
Основная идея состоит в неиспользовании операции умножения двух чисел. Легко понять, что если числа натуральные, то одна из пар должна содержать максимальное и минимальное числа. Рассуждая таким образом для оставшихся чисел, приходим к простому алгоритму. Упорядочиваем числа в порядке неубывания. Тогда пары составляют первое и последнее, второе и предпоследнее и т.д. Ситуация немного изменяется, если числа целые. В этом случае возможны три варианта:
1. Произведение равно 0. В этом случае существует хотя бы N нулевых элементов. Поэтому пары будут организованы из одного ненулевого элемента и одного нулевого или из двух нулевых элементов.
2. Произведение положительно. В этом случае перемножаются положительные с положительными, а отрицательные с отрицательными, по правилу как и в случае с натуральными числами.
3. Произведение отрицательно. В этом случае перемножается минимальное положительное число с минимальным отрицательным и т.д.
Для определения ситуаций достаточно подсчитать количество нулевых, положительных и отрицательных элементов.
Если есть нулевые элементы, то возможен только вариант 1. Если количество положительных не равно количеству отрицательных, то возможен только вариант 2. В других случаях возможна ситуация 2 и 3.
Для определения знака произведения рассмотрим четверку чисел: максимальный положительный (пусть a), минимальный положительный (b), минимальный отрицательный(c), максимальный отрицательный (d). Понятно, что решением могут быть только пары (a,b),(c,d) или (a,d),(b,c). Если a не равно -c, то в паре с элементом a должен быть меньший по модулю из элементов c, d, если a>-c и наоборот. В случае, если a=-c и b=-d, эта четверка не дает никакой информации о знаке произведения, поэтому можно перейти к следующей четверке чисел и т.д. пока не будет установлен знак произведения. Если же просмотрены все числа, а знак не установлен, то он может быть как плюс, так и минус.
Чтобы сумма произведений пар была максимальна (минимальна) необходимо упорядочить наборы A и B одинаковым (различным) образом и пары будут составлять элементы стоящие на одинаковых позициях в упорядоченных наборах. Это следует из того факта, что если а<b и c<d,то а*с+в*d>=a*d+b*c.
Будем представлять посещение музея посетителем в виде отрезка [время_прихода_посетителя, время_ухода_посетителя]. Надо найти множество точек, принадлежащих максимальному числу отрезков (они и будут составлять тот промежуток (промежутки) времени, в течение которого в музее одновременно находилось максимальное число посетителей.
Рассмотрим какой-нибудь такой промежуток. Его концами, очевидно, являются концевые точки каких-то двух отрезков. В решении задачи 8 (Дихотомия и поиск) в переменной С храниться количество отрезков, пересекающихся в текущей концевой точке. Сначала мы найдем Cmax - максимальную величину переменной C, затем определим, каким промежуткам соответствует максимальное количество посетителей в музее:
{смысл массива A см. в задаче 8 (Дихотомия и поиск)}
{находим Cmax}
i:=1; Cmax:=0;
пока (i<=2*N) и
повторять
если A[2,i]>0
то C:=C+1;
Cmax:=max(Cmax, C);
конец_то
иначе C:=C-1;
конец_иначе
i:=i+1;
конец_пока
если Сmax=0,
то посетителей не было вообще. Стоп.
{ищем и печатаем промежутки с максимальным числом посетителей}
i:=1;
пока (i<=2*N) и
повторять
если A[2,i]>0
то C:=C+1;
если С=Смах {это начало искомого промежутка?}
то печатаем координату начала промежутка A[1,i] конец_то
конец_то
иначе
если С=Смах {промежуток закончился}
то печатаем координату конца промежутка A[1,i]
конец_то
C:=C-1;
конец_иначе
i:=i+1;
конец_пока
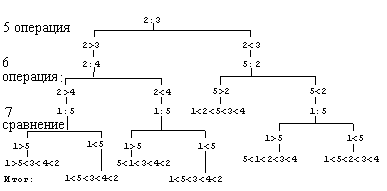
Предположим, что среди пяти чисел нет одинаковых (случай совпадающих чисел рассматривается аналогично). В дальнейшем будем обозначать операцию сравнения значком ':'. Например, 5:3 означает, что мы сравниваем пятое и третье числа. Запись 5<3 означает, что пятое число меньше третьего.
Сначала выполним следующие операции 1:2,3:4. При необходимости перенумеровывая числа, получаем, что 1<2, 3<4. Далее делаем 1:3. Опять же при необходимости перенумеровывая числа, получаем 1<3.
Выполняем 3:5. Случаи:
a) 3>5. Подводя итог четырех проделанных операций сравнения имеем:
1<2
1<3<4
5<3
б) 3<5.
Сравниваем 4 и 5.
Пусть 4<5. Тогда
1<2
1<3<4<5.
Выполняем 2:4. В зависимости от результата делаем либо 2:3, либо 2:5.
Зафиксируем какой-нибудь порядок перечисления ребер параллелепипеда.
Очевидно, что параллелепипеды можно повернуть так, чтобы размеры ребер параллелепипеда шли в неубывающем порядке. Опять же понятно, что параллелепипед с большим объемом нельзя вложить в параллелепипед с меньшим объемом, вложение параллелепипеда B в C возможно только тогда, когда для двух параллелепипедов B(b(1), ..., b(n)) и C(c(1), ..., c(n)) выполняются неравенства b(k)<=c(k), k=1, ..., n. Запишем это так:
(b(1), ..., b(n))<=(c(1), ..., c(n)).
Алгоритм:
1. Сортируем размеры граней каждого параллелепипеда в неубывающем порядке.
2. Сортируем последовательность параллелепипедов по неубыванию объема.
3. Применяем алгоритм задачи 20 (Глава "Рекуррентные соотношения и динамическое программирование") для поиска максимальной по длине возрастающей подпоследовательности.
Без потери общности предположим, что элементы массива A упорядочены в возрастающем порядке (в множестве нет дублирующихся элементов, поэтому массив A упорядочен именно в возрастающем, а не только в неубывающем порядке). Если это не так, то добавляем в программу подпpогpамму сортировки.
Если свойство (*) выполняется для подмножества B, то оно выполняется и для трех наибольших по величине элементов B. Обратно, из выполнимости (*) для трех максимальных элементов B следует выполнимость (*) и для B. Мы будем включать в B в порядке их возрастания элементы из A и проверять для трех максимальных выполнение (*).
Программа на Pascal будет выглядеть следующим образом:
const m=20; {максимальный размер массива A}
var A:array[1..m] of word; {описание массива A}
n,s,s3,k,:word;
{s -- сумма от 1-ого до i-ого элементов массива A
s3 - сумма a(i+1)+a(i+2)+a(i+3)
n - размерность массива A
k - индекс такого элемента массива A, что для a(1), ... ,a(k)
выполняется свойство (*)}
begin
readln(n);
for i:=1 to n do readln(a[i]);
k:=0;
for i:=1 to n-3 do
begin
s:=s+a[i];
s3:=a[i+1]+a[i+2]+a[i+3];
if s3<=s then k:=i+3;
end;
if k=0 then writeln('Решения нет')
else for i:=1 to k do write(a[i]);
end.
а) Пусть в переменной MaxEndingHere хранится сумма элементов максимального подвектора, заканчивающегося в позиции i-1. Для того, чтобы MaxEdingHere начала хранить сумму элементов максимального подвектора, оканчивающегося в позиции i, необходимо выполнить следующую операцию присваивания:
MaxEndingHere:=max(MaxEndingHere+A[i],A[i]);
а для того, чтобы найти максимальную сумму MaxSoFar элементов подвектора, встретившегося до позиции i, надо выполнить операцию
MaxSoFar:=Max(MaxSoFar, MaxEndingHere).
Программа:
MaxSoFar:=A[1];
MaxEndingHere:=A[1];
for i:=2 to K do begin
MaxEndingHere:=max(MaxEndingHere+A[i],A[i]);
MaxSoFar:=max(MaxSoFar, MaxEndingHere);
end.
b) Для поиска минимальной суммы мы можем сначала умножить все элементы массива A на -1, а затем искать, как и в пункте а, максимальную сумму.
c) Заведем массив C[0..k] такой, что C[i]=A[1]+ ... +A[i], C[0]=0. Заметим, что
S(M,N)=C[N]-C[M-1].
Сумма S(M,N) элементов вектора A[M]+ ... +A[N] равна нулю, если C[M-1]=C[N]. Исходя из этого соображения возьмем массив C, отсортируем его, затем найдем минимальную по модулю разность двух соседних элементов отсортированного массива (т.е. найдем два наименее отличающихся элемента массива C). Эта разность как раз и будет наиболее близким к нулю значением суммы S(M,N).
d) Как и в предыдущем пункте сформируем массив C, затем его отсортируем. Нам надо найти в этом массиве два элемента C[i] и C[j], значение разности которых наиболее близко к P. Пусть массив C упорядочен по неубыванию, и i и j - индексы текущих просматриваемых элементов массива C.
i:=1; j:=1;
MinSoFar:=abs(C[2]-C[1]-P); {Текущее значение минимальной разности}
while (i<=k) and (j<=k) do begin
if C[j]-C[i]>P
then i:=i+1; {увеличиваем вычитаемое}
else j:=j+1; {увеличиваем уменьшаемое}
if i<>j {если это не один и тот же элемент массива C}
then MinSoFar:=min(MinSoFar, abs(C[j]-C[i]-P));
end;
О применении аналогичных пунктам а)-d) методов решения задач - см. задачу 12 главы РЕКУРРЕНТНЫЕ СООТНОШЕНИЯ И ДИНАМИЧЕСКОЕ ПРОГРАММИРОВАНИЕ.
Можно в массив C записать сначала элементы массива A, затем массива B, затем применить любой алгоритм сортировки. Но в этом случае мы не используем того, что A и B уже отсортированы. Будем просматривать элементы массивов A и B начиная с A[1] и B[1]. Если, например, A[1]>B[1], то C[1]:=B[1], и на следующем шаге сравниваем уже A[1] и B[2], занося меньший элемент пары в ячейку C[2] и т.д.
Запись алгоритма на языке Паскаль:
{Ввод массивов A и B}
Ai:=1; Bi:=1; Ci:=1; {текущие индексы в массивах A,B,C}
while Ci<=N+M do begin
if A[Ai]>B[Bi]
then begin
C[Ci]:=B[Bi];
Bi:=Bi+1
end
else begin
C[Ci]:=A[Ai]; Ai:=Ai+1;
end
Ci:=Ci+1;
{Проверка окончания одного из массивов}
if Ai>N then for i:=Bi to M do
begin
C[Ci]:=B[Bi];
Bi:=Bi+1;
Ci:=Ci+1;
end;
if Bi>N then for i:=Ai to N do
begin
C[Ci]:=A[Ai];
Ai:=Ai+1;
Ci:=Ci+1;
end;
end; {while}
Пусть A - это k первых элементов массива X, а B - последних N-K. Нам необходимо из вектора AB получить вектор BA. Пусть у нас есть подпрограмма REVERRSE(I,j), которая реверсирует (меняет порядок элементов на обратный) часть массива x с индексами от i до j. Начав с массива AB реверсируем часть A, получаем (Ar)B; реверсируrем B, получаем (Ar)(Br); реверсируем весь массив, получаем((Ar)(Br))r =BA.
Продемонстрируем описанный алгоритм на примере. Пусть X есть последовательность 1,2,3,4,5, k=3:
Пусть числа a[1], ..., a[n] расположены в порядке неубывания (если это не так, то просто отсортируем массив). Будем выписывать искомые векторы v[1], ..., следующим образом:
Пусть k - номер формируемого сейчас вектора.
Положим сначала индекс i первого элемента формируемого сейчас вектора v[k] равным 1, а индекс второго элемента j=N.
k:=0;
пока (i<j) повторять {пока есть возможные элементы для пар}
k:=k+1;
v[k]:=(a[i],a[j]);
полагаем i:=i+1; j:=j-1; {переходим к следующим элементам}
если v[k]=(a[i],a[j])
то пусть количество оставшихся в массиве A элементов справа
от а[i-1], равных a[i-1], есть u, т.е. a[i]=a[i+1]=...=a[i+u],
а количество оставшихся в массиве A элементов слева от а[j+1],
равных a[j+1], есть v, т.е.
a[j]=a[j-1]=...=a[j-v].
если u>=v
то, так как мы стремимся получить максимальное число пар,
то мы отбросим все оставшиеся элементы со значением a[j]
и положим j:=j-v-1
иначе по аналогичной причине отбросим все оставшиеся элементы
со значением a[i], т.е. положим i:=i+u+1;
конец_если
конец_если
конец_пока