
|
Алгоритм k различий Ландау-Вишкина [Landau, Vishkin, 1986b, 1989] основан на подходе, близком методу динамического программирования для вычисления расстояния между строками, который предложил Укконен [Ukkonen, 1983, 1985a]. Перед тем, как перейти к этому алгоритму, опишем метод динамического программирования и его адаптацию в стиле Укконена.
Вспомним, что элемент di,j, определяемый (9), сообщает расстояние между префиксами с длинами i и j строк, соответственно, x и y. Чтобы решить задачу k различий, матрицу расстояний надо преобразовать таким образом, чтобы di,j представлял минимальное расстояние между x(1, i) и любой подстрокой y, заканчивающейся символом yj (Селлерс, 1980). Для этого достаточно изменить граничные условия (задаваемые (12)), на
|
d0,j = 0 для 0 < j < n
|
(59) |
так как минимальное расстояние между 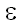 и любой подстрокой y равно 0. и любой подстрокой y равно 0.
Остальная часть матрицы вычисляется как раньше, с использованием цен редактирования расстояния Левенштейна, (10), и рекуррентного соотношения для di,j (11). По завершении, каждое значение, не превосходящее k, в конечной строке указывает позицию в тексте, в которой заканчивается строка, имеющая не больше k отличий от образца. Это иллюстрируется приведенным ниже примером, в котором показана матрица расстояния для случая x = ABCDE и y = ACEABPCQDEABCR. Из строки 5 этой матрицы можно видеть, что вхождения образца с точностью до 2 отличий, заканчиваются в позициях 3, 10, 13 и 1 Соответствующими подстроками являются ACE, ABPCQDE, ABC и ABCR.
|
|
j |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
|
i |
|
|
A |
C |
E |
A |
B |
P |
C |
Q |
D |
E |
A |
B |
C |
R |
|
0 |
|
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
1 |
A |
1 |
0 |
1 |
1 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
1 |
1 |
1 |
|
2 |
B |
2 |
1 |
1 |
2 |
1 |
0 |
1 |
2 |
2 |
2 |
2 |
1 |
0 |
1 |
2 |
|
3 |
C |
3 |
2 |
1 |
2 |
2 |
1 |
1 |
1 |
2 |
3 |
3 |
2 |
1 |
3 |
1 |
|
4 |
D |
4 |
3 |
2 |
2 |
3 |
2 |
2 |
2 |
2 |
2 |
3 |
3 |
2 |
1 |
1 |
|
5 |
E |
5 |
4 |
3 |
2 |
3 |
3 |
3 |
3 |
3 |
3 |
2 |
3 |
3 |
2 |
2 |
Вспомним, что, как описано в алгоритме Укконена, при вычисления расстояний между строками диагонали матрицы можно пронумеровать целыми числами p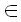 [-m, n], таким образом, чтобы диагональ p состояла из элементов (i, j), у которых j - i = p. Пусть rp,q представляет наибольшую строку i, у которой di,j = q и (i, j) лежит на диагонали p. Таким образом, q – это минимальное число различий между x(1, rp,q) и любой подстрокой текста, заканчивающейся [-m, n], таким образом, чтобы диагональ p состояла из элементов (i, j), у которых j - i = p. Пусть rp,q представляет наибольшую строку i, у которой di,j = q и (i, j) лежит на диагонали p. Таким образом, q – это минимальное число различий между x(1, rp,q) и любой подстрокой текста, заканчивающейся 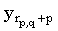 , и, кроме того, , и, кроме того, 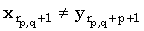 , так как в противном случае требуемым условиям удовлетворяла бы строка rp,q+1, которая больше строки rp,q. , так как в противном случае требуемым условиям удовлетворяла бы строка rp,q+1, которая больше строки rp,q.
Вернемся к нашему примеру. Ниже представлена диагональ 9 матрицы расстояний. Мы видим, что значениями rp,q в этом случае являются r9,0 = 0, r9,1 = 4 и r9,2 = 5.
|
|
j |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
|
i |
|
|
A |
C |
E |
A |
B |
P |
C |
Q |
D |
E |
A |
B |
C |
R |
|
0 |
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
1 |
A |
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
2 |
B |
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
3 |
C |
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
4 |
D |
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
5 |
E |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
Значение m в строке rp,q, для q < k, указывает, что в тексте имеется вхождение образца с точностью до k отличий, заканчивающееся в ym+p. Таким образом, чтобы решить задачу k различий, достаточно вычислить значения rp,q для q < k.
Чтобы объяснить, как можно вычислить значения rp,q, рассмотрим вычисление входов di,j в матрице динамического программирования. Если di,j = q, этот вход находится на диагонали p, и i является наибольшей строкой, удовлетворяющей этим требованиям, тогда по определению rp,q = i. Значение di,j будет выведено по одному из предшествующих ему соседних значений в матрице в соответствии с (11). При этом существуют следующие возможности:
-
di-1,j-1 = q и xi = yj
-
di-1,j-1 = q-1 и xi =/=yj
-
di,j-1 = q-1
-
di-1,j = q-1
Если последнее появление значения q-1 на диагонали уже найдено, последнее появление значения q на этой диагонали можно найти, проходя через последующие элементы диагонали, пока xi = yj.
Обратите внимание, что первое возможное вхождение образца с точностью до k отличий встречается в позиции текста j = m-k. Эта позиция в строке m лежит на диагонали -k, поэтому диагонали p < -k при вычислениях мы можем не рассматривать. Заметим также, что смежные элементы в матрице могут отличаться только на 0 или 1. Алгоритм, приведенный на рисунке 29, можно использовать для вычисления значений rp,q. Начальное значение строки r получают из предыдущих значений rp,q-1, rp-1,q-1 и rp+1,q-1, и последовательно увеличивают на единицу за один раз, пока не будет достигнуто правильное значение rp,q.
То, что алгоритм правильно вычисляет значения rp,q, можно показать следующим образом. Рассмотрим случай, когда q = 0 и вычисляются значения rp,0 (p > 0). Из граничных условий, начальное значение r равно 0. Цикл while находит, что x(1, rp,0) = y(p+1, p+rp,0) и 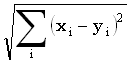 , устанавливая, таким образом, rp,0 равным правильному значению. Для диагоналей p < 0 правильные значения для rp,|p|-1 и rp,|p|-2 будут установлены во время инициализации. Пусть q = t, и предположим, что все значения rp,t-1 правильны. Рассмотрим вычисление rp,t (p > - t). Переменная r устанавливается равной наибольшей строке на диагонали p, такой, что dr,r+p может достичь величины t посредством возможностей 2, 3 или 4, описанных ранее. Цикл while после этого станет перебирать последующие позиции на диагонали, в которых символы шаблона и текста совпадают, пока не придет к правильном значению rp,t. , устанавливая, таким образом, rp,0 равным правильному значению. Для диагоналей p < 0 правильные значения для rp,|p|-1 и rp,|p|-2 будут установлены во время инициализации. Пусть q = t, и предположим, что все значения rp,t-1 правильны. Рассмотрим вычисление rp,t (p > - t). Переменная r устанавливается равной наибольшей строке на диагонали p, такой, что dr,r+p может достичь величины t посредством возможностей 2, 3 или 4, описанных ранее. Цикл while после этого станет перебирать последующие позиции на диагонали, в которых символы шаблона и текста совпадают, пока не придет к правильном значению rp,t.
- инициализация
rp,-1 = -1 for 0 < p < n
rp,|p|-1 = |p| - 1, rp,|p|-2 = |p| - 2 for -(k+1) < p < -1
rn+1,q = -1 for -1 * q * k
- вычисление значений rp,q
for q = 0 to k
for p = -q to n
r = max{rp,q-1 + 1, rp-1,q-1, rp+1,q-1 + 1}
r = min{r, m}
while (r < m) and (r + p < n) and (xr+1 = yr+1+p)
r = r + 1
rp,q = r
if rp,q = m then
имеется вхождение с k отличиями, заканчивающееся в yp+m
Рисунок 29: Вычисление rp,q методом динамического программирования
Алгоритм вычисляет значения rp,t на n+k+1 диагоналях. Для каждой диагонали переменной строки r можно присвоить не больше m различных значений, что приводит ко времени вычислений O(mn). Таким образом, временные затраты те же, что и у прямого метода динамического программирования, описанного ранее. Однако, теперь мы покажем, как структуру этого метода можно использовать для разработки более эффективного алгоритма.
Улучшение эффективности достигается за счет изменения метода вычисления rp,q. В описанном выше методе переменная r последовательно увеличивается на единичных шагах, пока не будет достигнуто правильное значение rp,q. Однако, благодаря подходящим предварительным вычислениям, значение rp,q можно находить за фиксированное время. Как это сделать, мы расскажем позже, однако сначала рассмотрим требуемые для этого предварительные вычисления.
Стадия предварительных вычислений включает построение так называемого суффиксного дерева, которое можно описать следующим образом. Рассмотрим строку s = s(1, q), где sq = $ – маркер конца, не являющийся частью алфавита, над которым построена строка s(1, q-1). Каждый суффикс s(i, q), 1 < i < q, строки s определяет один из листьев суффиксного дерева для s. Все ребра в дереве направлены от корня, и количество выходящих из каждого узла либо равно нулю (у листьев), либо > 2. Если s(i, i+p) – самый длинный общий префикс двух суффиксов s(i, q) и s(j, q), то есть s(i, i+p) = s(j, j+p) и si+p+1 =/=sj+p+1, то s(i, i+p) определяет внутренний узел дерева. Два узла, представляющих подстроку b и соответствующий префикс из нее a, соединены ребром только в том случае, если не существует узла, представляющего подстроку c, такого, что c является префиксом b и a является префиксом c. Прерывающий символ $ используется для того, чтобы разделять в дереве суффиксы s(i, q-1) и s(j, q-1), когда один из них является префиксом другого. Обратите внимание, что суффиксное дерево для данной строки уникально с точностью до изоморфизма графов. Структура данных суффиксных деревьев более подробно рассматривается в последующих разделах этой главы.
В качестве примера ниже приведено суффиксное дерево для строки EWEW$, в котором каждый узел помечен определяющей его подстрокой и номером в скобках.
корень --------------------------- (1) $
| |
| |
| ------------- (2) W ---------- (4) W$
| |
| |
| ----------- (5) WEW$
|
|
--------------- (3) EW -------- (6) EW$
|
|
------------ (7) EWEW$
При построении дерева подстрока, определяющая конкретный узел, может быть представлена своей длиной и начальной позицией в строке. Эти значения для данного суффиксного дерева приведены ниже, где индексы представляют соответствующий номер узла.
start1 = 5 lenght1 = 1
start2 = 4 lenght2 = 1
start3 = 3 lenght3 = 2
start5 = 2 lenght5 = 4
start6 = 3 lenght6 = 3
start7 = 1 length7 = 5
На этапе предварительной обработки, суффиксное дерево строки y#x$, где # и $ – символы, не принадлежащие алфавиту, над которыми построены строки x и y, строится с помощью алгоритма Вейнера [Weiner, 1973] (который подробно описан Ченом и Сейферасом [Chen, Seiferas, 1985). Этот алгоритм требует линейных затрат памяти, и, для алфавита фиксированного размера, линейного времени. Для неограниченных алфавитов этот алфавит можно преобразовать, так что он будет выполняться за время O(n log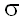 ), где – число различающихся символов образца. Стадия предварительной обработки требует время O(n) и O(n log m) для постоянного и неограниченного алфавитов, соответственно. Альтернативные способы предварительной обработки с использованием суффиксных деревьев рассматривались Галилом и Джанкарло (1988). ), где – число различающихся символов образца. Стадия предварительной обработки требует время O(n) и O(n log m) для постоянного и неограниченного алфавитов, соответственно. Альтернативные способы предварительной обработки с использованием суффиксных деревьев рассматривались Галилом и Джанкарло (1988).
Теперь можно модифицировать алгоритм, приведенный на рисунке 29, чтобы воспользоваться преимуществами вышеуказанной предварительной обработки. Непосредственно перед циклом while для диагонали p, r было присвоено значение, такое, чтобы x(1, r) сопоставлялось с точностью до k различий с некоторой подстрокой текста, заканчивающейся yr+p. Тогда функция цикла while находит максимальное значение, назовем его h, для которого x(r+1, r+h) = y(r+p+1, r+p+h). Это эквивалентно нахождению длины самого длинного общего префикса суффиксов x(r+1, m)$ и y(r+p+1,n)#x$ предварительно вычисленной конкатенированной строки. Символ # используется для предотвращения ситуаций, в которых может ошибочно рассматриваться префикс, состоящий из символов как y, так и x. Если lca(r,p) определяется как самый низкий общий предок (LCA) в суффиксном дереве с листьями, определенными вышеуказанными суффиксами, нужное значение h задается lengthlca(r,p). Таким образом, алгоритм самого низкого общего предка Харела и Тарьяна [Harel, Tarjan, 1984] или Шибера и Вишкина [Schieber, Vishkin, 1988] может использоваться в алгоритме k различий в качестве средства, альтернативного выводу длин нужных сопоставляемых подстрок.
Суффиксное дерево имеет O(n) узлов. Для поддержки определения самого низкого общего предка за линейное время, алгоритмам LCA (самого низкого общего предка) требуется преобразование дерева, проводимое за линейное время. Как упоминалось ранее, значения rp,q вычисляются на n+k+1 диагоналях. Более того, для каждой диагонали надо вычислить k+1 таких значений, что в общей сложности дает O(kn) запросов. Эти вычисления с временем O(kn) дают наибольший вклад в вычисление значений rp,q. Таким образом, общее время прогона для этого алгоритма k различий составляет O(kn) для алфавитов фиксированного размера, и O(n * log(m) +kn) для неограниченных алфавитов.
Кроме того, Ландау и Вишкин [Landau,Vishkin, 1986b, 1989] разработали параллельную версию вышеприведенного алгоритма. Суффиксное дерево может быть вычислено за время O(log n) с использованием n процессоров (Ландау, Шибер и Вишкин [Landau, Schieber, Vishkin, 1987]; Апостолико et al. [Apostolico et al., 1988]). Параллельный алгоритм Шибера и Вишкина может использоваться для предварительной обработки дерева за время O(log n) с использованием n/log n процессоров, при условии, что отдельный процессор выполняет последовательный запрос самого низкого общего предка за время O(1). Таким образом, использование n+k+1 процессоров позволяет выполнять все требуемые запросы самого низкого общего предка за время O(k), – граница, которая также может быть достигнута моделированием алгоритма на n процессорах. Итак, общее требуемое время равно O(log n+k) для n процессоров. Кроме того, Ландау и Вишкин обсуждают, как геометрическая декомпозиция задачи может привести к адаптации алгоритма, по прежнему требующей n процессоров, но выполняющейся за время O(log m).
|