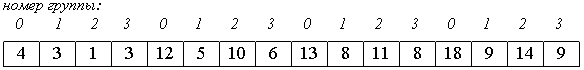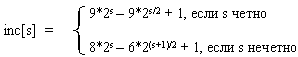|
Сортировка Шелла является довольно интересной модификацией алгоритма сортировки простыми вставками.
Рассмотрим следующий алгоритм сортировки массива a[0].. a[15].
1. Вначале сортируем простыми вставками каждые 8 групп из 2-х элементов (a[0], a[8[), (a[1], a[9]), ... , (a[7], a[15]).
2. Потом сортируем каждую из четырех групп по 4 элемента (a[0], a[4], a[8], a[12]), ..., (a[3], a[7], a[11], a[15]).
В нулевой группе будут элементы 4, 12, 13, 18, в первой - 3, 5, 8, 9 и т.п.
3. Далее сортируем 2 группы по 8 элементов, начиная с (a[0], a[2], a[4], a[6], a[8], a[10], a[12], a[14]).
4. В конце сортируем вставками все 16 элементов.
Очевидно, лишь последняя сортировка необходима, чтобы расположить все элементы по своим местам. Так зачем нужны остальные ?
Hа самом деле они продвигают элементы максимально близко к соответствующим позициям, так что в последней стадии число перемещений будет весьма невелико. Последовательность и так почти отсортирована. Ускорение подтверждено многочисленными исследованиями и на практике оказывается довольно существенным.
Единственной характеристикой сортировки Шелла является приращение - расстояние между сортируемыми элементами, в зависимости от прохода. В конце приращение всегда равно единице - метод завершается обычной сортировкой вставками, но именно последовательность приращений определяет рост эффективности.
Использованный в примере набор ..., 8, 4, 2, 1 - неплохой выбор, особенно, когда количество элементов - степень двойки. Однако гораздо лучший вариант предложил Р.Седжвик. Его последовательность имеет вид
При использовании таких приращений среднее количество операций: O(n7/6), в худшем случае - порядка O(n4/3).
Обратим внимание на то, что последовательность вычисляется в порядке, противоположном используемому: inc[0] = 1, inc[1] = 5, ... Формула дает сначала меньшие числа, затем все большие и большие, в то время как расстояние между сортируемыми элементами, наоборот, должно уменьшаться.
Поэтому массив приращений inc вычисляется перед запуском собственно сортировки до максимального расстояния между элементами, которое будет первым шагом в сортировке Шелла. Потом его значения используются в обратном порядке.
При использовании формулы Седжвика следует остановиться на значении inc[s-1], если 3*inc[s] > size.
int increment(long inc[], long size) {
int p1, p2, p3, s;
p1 = p2 = p3 = 1;
s = -1;
do {
if (++s % 2) {
inc[s] = 8*p1 - 6*p2 + 1;
} else {
inc[s] = 9*p1 - 9*p3 + 1;
p2 *= 2;
p3 *= 2;
}
p1 *= 2;
} while(3*inc[s] < size);
return s > 0 ? --s : 0;
}
template<class T>
void shellSort(T a[], long size) {
long inc, i, j, seq[40];
int s;
// вычисление последовательности приращений
s = increment(seq, size);
while (s >= 0) {
// сортировка вставками с инкрементами inc[]
inc = seq[s--];
for (i = inc; i < size; i++) {
T temp = a[i];
for (j = i-inc; (j >= 0) && (a[j] > temp); j -= inc)
a[j+inc] = a[j];
a[j+inc] = temp;
}
}
}
Часто вместо вычисления последовательности во время каждого запуска процедуры, ее
значения рассчитывают заранее и записывают в таблицу, которой пользуются, выбирая начальное приращение по тому же правилу: начинаем с inc[s-1], если 3*inc[s] > size.
|