Вейвлет-анализ и его приложения
Лекция 2
Лифтинг. Мультивейвлеты
В последней лекции курса мы расскажем о некоторых современных тенденциях развития теории и практики вейвлет-преобразований: методе лифтинга, позволяющем эффективно реализовывать существующие и конструировать новые схемы вейвлет-преобразований, а также о мультивейвлетах -- векторнозначном расширении вейвлетов.
Лифтинг.
Целочисленное вейвлет-преобразование
Напомним условия точного восстановления для двух пар биортогональных фильтров. Рассмотрим две пары фильтров:
Записав в аналогичном виде процесс восстановления
с помощью пары ![]() ,
и приравняв результат к
,
и приравняв результат к ![]() ,
получаем :
,
получаем :
(1)
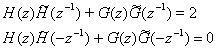
- Метод лифтинга (lifting) позволяет:
- Строить новые фильтры, удовлетворяющие (1), из уже имеющихся.
- Выполнять вейвлет-преобразование быстрее за счет декомпозиции на элементарные шаги лифтинга (lifting steps).
(2)
(1’)
Мы предполагаем, что все фильтры содержат
конечное число ненулевых коэффициентов, т.е. выражения типа ![]() являются многочленами Лорана (могут
содержать и положительные и отрицательные степени z);
для краткости будем называть их просто многочленами. Введем четную и нечетную
части наших многочленов :
являются многочленами Лорана (могут
содержать и положительные и отрицательные степени z);
для краткости будем называть их просто многочленами. Введем четную и нечетную
части наших многочленов :
Полифазная матрица имеет вид:
Она связана с матрицей модуляции так:
Подставив это выражение в (1’), получим условие точного восстановления в такой форме:
(3)
Полифазная матрица позволяет записать вейвлет-преобразование через действие компонент фильтров на компонентах сигнала. Например, этап разложения выглядит так:
Предположим, что имеется пара фильтров ![]() ,
такая, что
,
такая, что ![]() .
Такая пара называется комплементарной (complementary). Оказывается,
легко описать все конечные фильтры
.
Такая пара называется комплементарной (complementary). Оказывается,
легко описать все конечные фильтры ![]() ,
образующие комплементарную пару с фиксированным фильтром
,
образующие комплементарную пару с фиксированным фильтром ![]() .
А именно, пара
.
А именно, пара ![]() комплементарна тогда и только тогда, когда:
комплементарна тогда и только тогда, когда:
Это преобразование пары фильтров называется лифтингом. Оно эквивалентно преобразованию полифазной матрицы:
Ясно, что при этом определитель остается равным 1. Дуальная полифазная матрица преобразуется так:
Новый дуальный фильтр ![]() имеет вид:
имеет вид:
Дуальный лифтинг (dual lifting)
дает полное описание фильтров ![]() ,
образующих комплементарную пару с фиксированным фильтром
,
образующих комплементарную пару с фиксированным фильтром ![]() :
:
где T – произвольный многочлен.
Такое преобразование пары фильтров называется дуальным лифтингом. Оно эквивалентно преобразованию полифазной матрицы:
При этом дуальный фильтр ![]() автоматически становится таким:
автоматически становится таким:
При помощи алгоритма Евклида вычисления наибольшего общего делителя многочленов можно получить следующее разложение полифазных матриц (основной и дуальной):
(4)
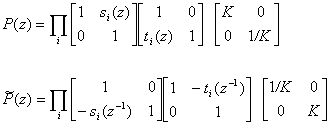
Очень кратко это можно пояснить так: алгоритм
Евклида, примененный к паре 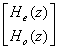 ,
дает разложение
,
дает разложение 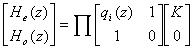 .
Матрицы, входящие в это разложение, легко преобразовать к лифтинговому
виду.
.
Матрицы, входящие в это разложение, легко преобразовать к лифтинговому
виду.
Обратим внимание на то, что масштабирование,
заданное в (4) матрицей ![]() также можно представить в виде шагов лифтинга, причем не единственным образом.
Вот один из вариантов:
также можно представить в виде шагов лифтинга, причем не единственным образом.
Вот один из вариантов:
(4’)
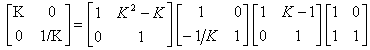
Какая может быть польза от разложения (4’), мы увидим чуть позже.
Разложение (4) – “анатомия” одного шага вейвлет-преобразования. Любое биортогональное ВП можно представить в таком виде. Непосредственный результат – сокращение числа операций (до 50%). Но главное значение лифтинга не в этом. Если перейти от z-преобразования к записи в компонентах самого сигнала, то полученные формулы удобно модифицировать для локальной адаптации к сигналу, а также к краевым условиям. Этот подход очень близок к тому, который использовался при построении адаптивных многосеточных разностных схем в вычислительной физике.
Идея лифтинга близка к идее пирамиды лапласианов. Однако первоначально лифтинг возник в рамках идеологии предсказания-уточнения (predict-update). Применение лифтинговых матриц-сомножителей к сигналу эквивалентно следующей процедуре. Исходный сигнал разбивается на 2 компоненты (например, четную и нечетную). Нечетные элементы “предсказываются” по значениям четных, находится разность (ошибка предсказания), а затем по этой ошибке корректируется четная часть (например, чтобы сохранить неизменным среднее значение). Например, можно предсказывать нечетные компоненты сигнала по четным при помощи кубической интерполяции.
Запишем шаги схему лифтинга в терминах компонентов векторов:
(5)
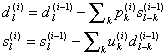 ,
,где ![]() — нечетные компоненты,
— нечетные компоненты, ![]() — четные компоненты исходного сигнала,
— четные компоненты исходного сигнала, ![]() — компоненты некоторых фильтров, определяемых конкретной схемой. Последним
шагом, согласно (4), является масштабирование:
— компоненты некоторых фильтров, определяемых конкретной схемой. Последним
шагом, согласно (4), является масштабирование:
(5’)
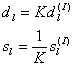 ,
,однако из (4’) следует, что и масштабирование можно представить в виде (5).
В результате применения шагов лифтинга к сигналу x получим “низкочастотную” s и “высокочастотную” d составляющие сигнала.
Обратное преобразование, очевидно, получается выполнением тех же шагов в обратном порядке и “с изменением знаков”.
В качестве примера покажем, как в виде
шагов лифтинга записывается ненормализованное преобразование Хаара (фильтры ![]() ,
, ![]() ,
, ![]() ,
, ![]() ):
):
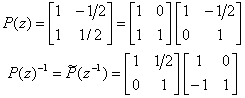
Шаги прямого преобразования:
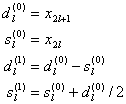
Шаги обратного преобразования:
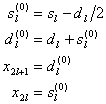
Как было отмечено выше, лифтинг позволяет не только анализировать имеющиеся фильтры, но и строить новые, то есть конструировать новые схемы вейвлет-преобразований, в том числе и такие, которые другим способом получить либо очень трудно, либо невозможно (в частности, преобразования, базисные функции которых не являются сдвигами и сжатиями одной функции). Идеология "предсказание-уточнение" является в этом смысле чем-то вроде итерационного метода пострения фильтров: взяв в качестве начального приближения набор "плохих" фильтров, можно, последовательно применяя к этим фильтрам шаги лифтинга, получать новые фильтры с определенными свойствами. При этом, если исходные фильтры удовлетворяют (1), то на каждом шаге лифтинга условие (1) не будет нарушаться , то есть любое построенное таким образом преобразование заведемо гарантирует точное восстановление.
В качестве начального приближения обычно берутся фильтры, выделяющие соответственно четные и нечетные компоненты исходного сигнала. В терминах вейвлетов это означает, что вейвет-базисом становится просто подмножество скейлинг-функций. Такие вейвлеты называются ленивыми (lazy wavelet), они практически неприменимы для сколь-либо удовлетворительной обработки сигналов, зато активно используются в качестве "заготовки" для построения констукций различной сложности.
Лифтинговая запись имеет еще одно полезное свойство: если компоненты сигнала – целые числа, то можно сделать целыми и все промежуточные результаты шагов лифтинга. При этом обращение остается точным, т.к. представляет собой те же самые шаги, выполненные в обратном порядке. Тем самым любое ВП можно заставить переводить целые числа в целые. Шаг целочисленного (integer-to-integer) ВП записывается с помощью лифтинга так:
(6)
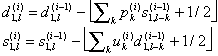
Основное преимущество целочисленного ВП в том, что оно допускает фактически точное восстановление сигнала, в то время как обычное преобразование может привести к искажению информации за счет ошибок округления.
Оказывается, что целочисленное ВП можно использовать при сжатии изображений без потерь, хотя имеются только предварительные результаты, указывающие на то, что после целочисленного ВП применение обычных методов символьного кодирования становится более эффективным.
Имеется и нелинейная версия предсказания-уточнения. Дело в том, что при работе в окрестности резких перепадов любые фильтры, полученные из интерполяционных соображений, дают плохой результат и при предсказании, и при уточнении. Нелинейность возникает в тех методах, где сигнал предварительно тестируется на локальные скачки, и предсказание делается по участкам, не содержащим скачков. Такого рода адаптация к сигналу хорошо известна в вычислительной физике, и в применении к многомасштабному разложению сигналов была впервые, по-видимому, реализована А.Хартеном в рамках его общей теории многомасштабного представления (см. [1]).